こちらです。
とにかくカジュアルに、簡単でもいいので正規表現を使いたい場面にマッチすると思う。
簡単なベンチを取った。
他の主要な3つのmgem(mruby-onig-regexp/mruby-regexp-pre/mruby-pure-regexp)と比較して、結果的に mruby-posix-regexp が一番ビルド時間、バイナリサイズともに小さくなるという結果になった。
ベンチの内容
まず、 mruby 3.0.0 において、以下ような最小限の build_config.rb を用いた。
MRuby::Build.new do |conf| conf.toolchain conf.gem mgem: 'mruby-onig-regexp' #conf.gem mgem: 'mruby-regexp-pcre' #conf.gem mgem: 'mruby-pure-regexp' #conf.gem mgem: 'mruby-posix-regexp' conf.gem core: 'mruby-bin-mruby' end
比較内容として、
rake deep_clean後に一からビルドした際のビルド所要時間- 生成された mruby バイナリのサイズ
を比較した。コマンドの例:
$ rake deep_clean $ time env MRUBY_CONFIG=onig_re rake .... real 0m44.950s user 0m38.223s sys 0m2.880s $ ls -l bin/mruby -rwxrwxr-x 1 vagrant vagrant 5532312 Sep 22 16:03 bin/mruby
またパフォーマンスのベンチとして、以下のスクリプトを走らせた。
text = "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum." text = ([text] * 100).join ' ' r = 0 100.times do r = text.scan(/\w+/).size end # mruby-io を含まないので例外で件数を出力している raise "size of words: #{r}"
なお、正常に終了した場合 6900 を出力する。
$ time ./bin/mruby ../scan.rb trace (most recent call last): ../scan.rb:8: size of words: 6900 (RuntimeError) real 0m1.084s user 0m1.071s sys 0m0.013s
検証環境は 15 コア、8GBのメモリを割り当てたVirtualBox上のVM(母艦のMacはIntel(R) Core(TM) i9-9980HK CPU @ 2.40GHz、16コア)とした。ただ、mrubyは並行ビルドや並行実行をしないのでコア数の影響は小さいのではないかと思う。
検証結果
| - | onig | pcre | pure | posix |
|---|---|---|---|---|
| ビルド所要時間(s) | 44.95 | 33.745 | 29.37 | 27.699 |
| バイナリサイズ(bytes) | 5532312 | 4477416 | 4137960 | 3956200 |
| ベンチ時間(s) | 1.084 | 5.395 | -(*1) | 4.307 |
(*1) 実行中にOOMによりKillされてしまったため計測できず。実行結果の出力を参考までに:
$ time ./bin/mruby ../scan.rb Killed real 0m5.271s user 0m2.508s sys 0m2.751s
グラフ
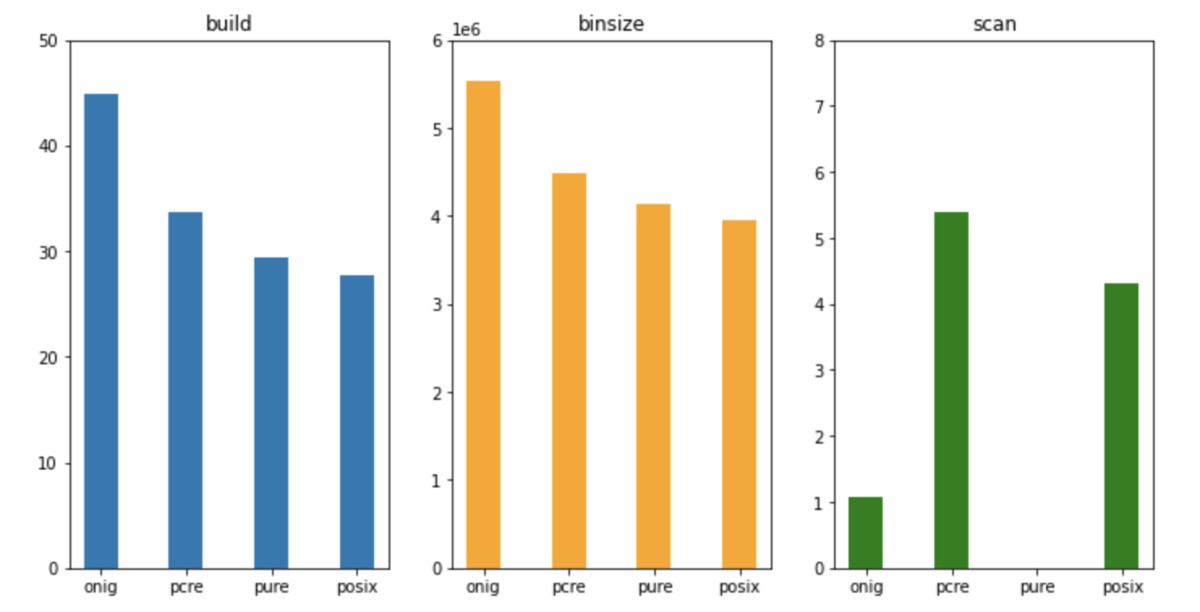
考察
- 依存ライブラリを小さく(より正確には、C拡張として外部ライブラリをビルドしないようにしたかった)、インストールを気軽にと考えて作ったものだが、結果的にC拡張部分がない mruby-pure-regexp よりもビルド時間・バイナリサイズとも若干小さくなった。
- 実行速度だけで見るとOnigmoがとんでもなく高速なので、引き続き普通のmrubyアプリケーションでは最も使われる選択肢になるのは間違いなさそう。
- posix regexpなので、 「いつものRubyの正規表現」はことごとく使えないと考えた方がいい と思う。例えば
\A\z\dなどは使えない。それで構わない人が使うことになる。
微妙に使いどころがなさそうだが、本当にちょびっと使いたいだけなのにバイナリサイズやビルド時間が増大するのは... というニッチな場面ではいいのかも。
ちなみに、 mruby-optparse が正規表現に依存するという話があり、ちょっとしたツールでOnigmoがバンドルされがちであったが、GNU正規表現である程度動くようにしたフォークを以下に作っている(もっとテストケース増やさないと不安だけど...)。
まとめ
ニッチな正規表現クラス実装 mgem を作った。
テストケースを足してくれたりする人を歓迎しています。