在经历数个月的探索后,国内首批大模型的行业落地进展浮出水面,而这些代表性企业的动作引发业界关注。
大模型已给一些行业带去质变,但也并不像当初憧憬的那样丰富多彩,而开源大模型给市场界格局带来变数,产业界暗流涌动。
01 浮出水面的行业实践
8月15日,在北京举办的百度WAVE SUMMIT 2023峰会期间,国家电网智研院知识计算技术主管张强分享了大模型在国网电力设备运检上的落地探索。
“整个电网的设备规模超过了4万亿,而与设备相关的标准、产品资料、故障案例等,是国网公司重要的数据资产和生产要素。”张强说。目前大模型实践以设备为核心切入点。会后,张强打开手机上的工作App为数智前线演示,相关业务模块已接入大模型,基层班组可获得设备运检中的相关判据和依据来源。
区别于互联网行业,工业的专业知识样本稀缺,积累困难,大模型的训练过程,也是对这些数字资产的系统化梳理和重构过程,这期间有很多挑战。现在,国网智研院的行业预训练语言模型参数超过70亿,正在进行150亿参数的电力认知大模型全量精调训练。
一位物联网技术专家告诉数智前线,类似国网,他们落地中进度较好的也是面向内部员工的文档知识问答。此前,员工检索企业内部文献文档很费劲。原先知识图谱技术手段,成本高,需要标注很多数据,训练很多小模型,而回答问题的覆盖度还较低。有了大模型,只要把文档做简单预处理,“丢给”大模型,大模型学习后就能直接回答问题,还能提供知识溯源出处,回答的覆盖度也较高,“这是对原来知识管理赛道很大的颠覆”。
除了能源企业,在7月华为开发者大会HDC期间,工商银行人工智能和大数据实验室副总经理黄炳也介绍了大模型的初步实践,例如辅助客服人员,能将专业知识转化为“大白话”的知识运营助手,为投研团队提供晨报的生成服务,以及工行办公系统中的文案创作、网讯编写、会议摘要等。有趣的是,网讯编写经过模型训练,会有“工行文风”。
黄炳介绍,这些场景都是人机协作,对员工和管理层有感知。比如,投研团队用的晨报生成服务,过去雇佣实习生花费1个小时,现在只需5分钟。
在能源、金融之外,上市公司中康科技首席技术官唐珂轲在WAVE SUMMIT期间告诉数智前线,基于通用大模型训练的行业模型,在三类医药相关场景中*落地。
其中一类是与几家连锁药店做的药事服务,可提升店员的专业度;一类是辅助医生的临床科研,比如文献整理和自动总结、医疗领域专业的Meta分析。“以前做一篇Meta分析至少3~6个月,现在只需花10分钟。”唐珂轲说,自己之前做过科研,能感知到大模型对临床科研效率上质的改变。第三类是患者出院后的健康管理,这部分此前基本是缺失的。他们目前在广东、湖南等地,与不同医院落地了针对不同肿瘤的模型,支撑乳腺癌、肝癌、肺癌等患者出院后的服务,这是肿瘤患者非常需要的。
唐珂轲称,医疗数据相对的封闭性,会给行业模型训练带来挑战。但他看好大模型对行业的前景改变。“去年在搭建患者回访系统时,技术实施复杂度“令人头疼”,但今年在大模型基础上投喂几千条数据,效果就不错”。
上海南洋万邦智能物联部经理曾佑轩告诉数智前线,在落地实践中,大模型在AI助手、知识管理两大方向上落地较多。该公司是上海仪电下属的数科公司。谈到大模型成本,曾佑轩介绍,目前AI助手的费用已做到每月每人10元。这并不像大家想象中那么高昂。
大模型已在为企业降本增效。一位云计算资深人士告诉数智前线,他了解原来某大型家具企业,外包客服要请数百人,现在已缩减到小几十人。“像这种项目,企业几十万可以搞定,又能节约成本,是比较好的落地。”
02 “大家都冷静理性了”
在大模型的落地实践中,行业对大模型有了更深入的认知,很多企业调整了预期,“大家冷静理性了。”
“我们从今年初开始重点关注大模型,当时的想法是要把大模型更好地用起来。”一位能源大企业人工智能专家近日告诉数智前线,“但在逐渐用的过程中,我们发现不是那么理想,也不会那么快。”
他们现在偏向于先支撑内部人员,因为“大模型的回答,尤其是事实类的还不是太好”,直接开放给客户还有一定风险。而面向内部,会经过大家的过滤、判断和把关。内部人员再结合他们的理解,对外来服务。“我们会灰度地去过渡,逐步开放一些功能。”
无独有偶,工行目前的应用也先从内部开始,优先面向金融文本和金融图像分析创作,且“场景肯定有错误容忍度”。
实际上,大模型的实际落地与当初的预期存在一定落差。“大模型能解决的问题,比一开始想象的要少很多。”一位行业资深人士告诉数智前线。
造成这个落差的原因有多方面。从场景上说,ChatGPT刚出来时,大家对大模型有很多憧憬,一位云计算人士举例,曾有企业找他咨询,AI能不能替代采购,因为采购环节最易滋生腐败,老板都想把这块监管或考虑用技术取代。但采购不是一个简单决策,需要综合考量。
“很多企业要么完全不知道怎么用,要么就是天马行空,但因为提出的场景复杂、决策链太长,实际做不到。”他说。而另一些人士认为,大家可能把大模型与通用人工智能混为一谈。
从技术角度看,在医疗、教育等一些专业度、准确度要求高的客服场景,大语言模型的幻觉是个问题。当他们把行业数据注入到基础大模型时,不管是微调,还是其他手段,模型能吸纳并能转化成正确输出的,大概有70%到80%。这就要求不得不用更多办法,去处理那20%到30%的错误率。
“但目前没有特别低成本和快速的办法。”上述人士反馈,很多东西需要去做强化学习和复杂的人工标定,所花的成本可能是现在成本基础再乘以10甚至更多,这让很多企业难以接受。
针对上述两个问题,聚焦领域大模型开发的中关村科金技术副总裁张杰告诉数智前线,在场景选择上,他觉得接下来适合大模型进一步落地的较好赛道,是专业性较高,且容错性较高的场景,如企业知识问答、营销机器人、坐席助手。而通用性太高或容错性又比较低的场景,如自动驾驶,不是特别好的商业赛道。
从技术层面,张杰认为不是某一套大模型的应用技术路线,就可以非常*地解决问题,他介绍了三种由浅入深的应用技术路线。

从落地实践看,目前,前两种接受度高。“这三种方法不是3选1,在具体场景下,肯定是一套组合拳。”他补充道。
“大家其实看到iPhone在2006就出来了,但整个移动互联网时代的开启是在2012年。”中信建投证券研究所所长、武超则在不久前的行业会议上称,“这个过程才刚刚开始”。
她认为大模型有几个阶段的演进,从能听会说、能看会认开始,到能够像人一样去组合使用工具,从而让每个人配一个“斯坦福毕业的助理”,再到通用人工智能中的会规划、会决策。
行业在不断深入探索。一位行业资深人士告诉数智前线,他们在做教育等行业,客户数量较大,在将大模型融入业务工作流的过程中,遇到很多问题,“还在去寻找有没有更能解决问题的方式”。
03 企业纷纷涌向开源大模型
在大模型落地的过程中,越来越多的国内企业开始采用开源大模型。
一位南方电网人士告诉数智前线,内部现在进行大模型尝试时,“都是基于Llama吧”。Meta公司在今年7月发布了开源可商用大模型Llama 2,包含了70亿、130亿和700亿参数3个版本。另一位南方电网人士称,内部对不同开闭源模型正进行测试赛马。
8月,金蝶发布的财务大模型,也基于开源大模型训练而来。金蝶CTO赵燕锡告诉数智前线,就像手机操作系统有iOS、安卓一样,开源模型要打造生成式AI的安卓系统,国内有像清华ChatGLM,国际上有MPT、Llama,未来是一个多模型合作的想法。
在金融领域落地中,有资深人士告诉数智前线,开源、闭源大模型都有,因为各金融机构体量不一,策略也不一样。很多公司先在一个具体场景下用开源模型做出实际效果,再考虑复制推广,也有几个大行对平台做一些战略性投入,在闭源基础大模型上,建了一个类似于中台的平台,期望将来同时对接多个场景。“不过,这种想法的客户数量较少,而且就现在他们测试的结果而言,也没有达到预期。”
“之前我们自己训练了两个不同参数的模型,最近我们也在用开源。”中科深智CTO宋健告诉数智前线。他认为,目前绝大部分文本写作、上下文匹配,130亿参数的模型已够用,而三四百亿参数的模型,在解决很多垂类问题上已经足够,无论国内百川,还是国外的Llama,效果都不错。
一家物联网公司技术高管告诉数智前线,目前开源大模型发展较快,开源社区也发布了很多模型,大部分基于Llama 2微调而来。“我们也测试过很多开源和闭源模型,由于我们的目标市场需要多语言支持,会更多考虑Llama 2。如果是面向国内市场,一些国内的模型也很优秀。”
“选择开源和闭源,实际上各有优缺点。使用开源模型的好处主要是较为自由,包括部署、微调、升级和免费。闭源的好处是有质量保证,免自己部署和应用门槛较低。”上述资深人士介绍。
他选择开源的一个重要原因是认为,目前开源模型的繁荣和水平提高呈现一个明显趋势。他打了一个比喻,开源大模型的水平就好比海平面,闭源大模型相当于一个个岛屿。目前这些岛屿上涨的速度,跟不上海平面上涨的速度,大部分岛屿将会被海水淹没,可能世界上最后就剩下几座上涨比较快的岛屿。
模型本身现在可选的很多,多位业内人士也赞同,开源和闭源不是客户会关心的问题,“极少客户会去指定用哪一款模型”。因为客户并不直接使用基础大模型,最终客户是没有感知的。“客户更关心的是精度、速度和价格。当然最终保证无害性、合法性,这是应用开发商必须解决的问题。”上述物联网行业专家说。
张杰告诉数智前线,因为开源可商用大模型,每一款可能都有自己的优缺点,比如说有些适合做一些分类型的任务,有些性能比较好,有些可能就生成式的任务表现比较好,还是要根据具体场景,一些ROI的需求,选择不同的模型。
“总体来讲,我们觉得接下来大模型非常重要的趋势,就是开源。”中信建投证券武超则称,非标准化的场景,非标准化的算力,这种架构决定开源可能会是一个比较趋同的方向。
04 大厂态度发生变化
开源世界的迅速繁荣,也正导致大模型生态链企业甚至底层芯片厂商的态度和策略发生一些微妙变化。
一家国内主流AI芯片企业人士告诉数智前线,Meta推出Llama 2开源模型后,呈现出的效果较好,这对目前市场上一些大模型来说是个绝杀。为此,他们已暂缓了对一些大模型的适配工作,观望一下再说。
国内外大模型大厂也已迅速在策略上做出改变,普遍朝着“左手闭源,右手开源”的方向走。
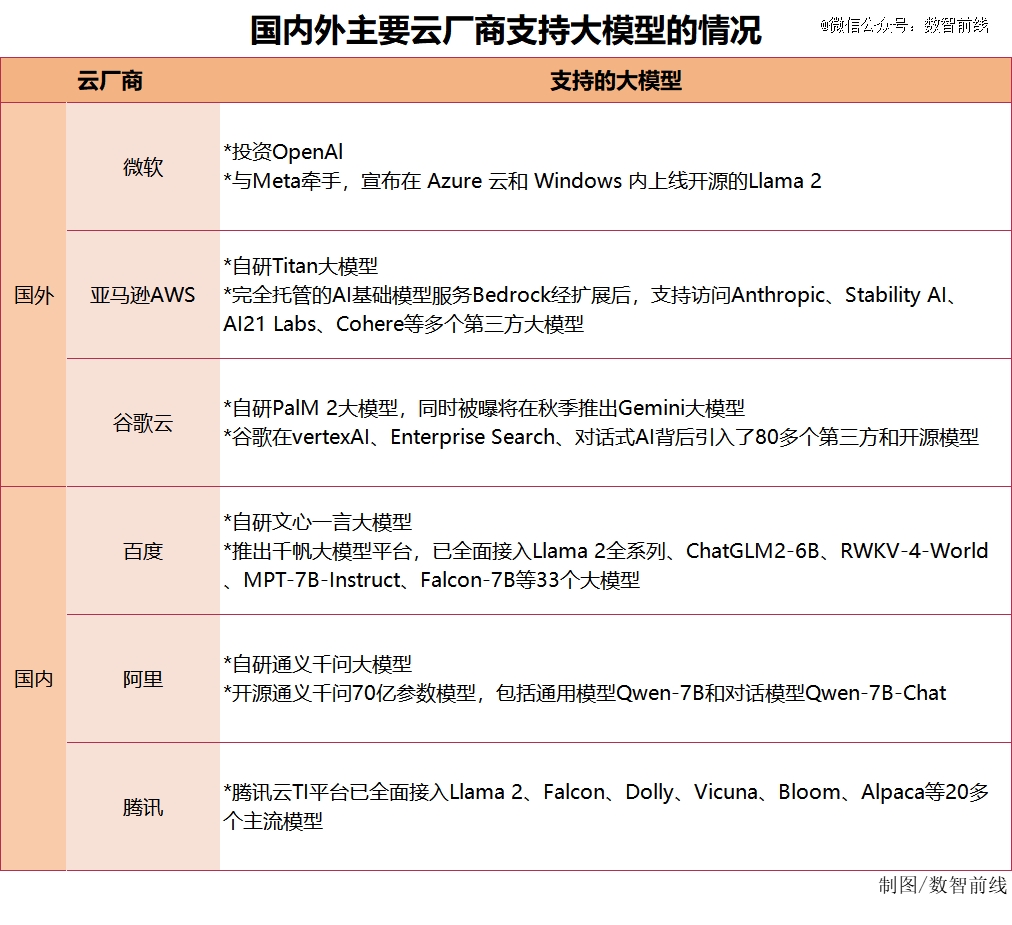
在国外,微软除了投资OpenAI闭源大模型,也和Meta实现牵手,宣布在其Azure云和Windows内上线开源的Llama 2。亚马逊AWS、谷歌云也都在自研大模型基础上,支持第三方和开源模型。
在国内,8月初,百度先宣布升级千帆大模型平台,接入Llama2全系列、清华ChatGLM2、RWKV等33个大模型,并对这些模型进行性能增强、推理优化等工作;之后,阿里开源通义千问70亿参数模型,包括通用模型Qwen-7B和对话模型Qwen-7B-Chat,称“开源、免费、可商用”;而在8月16日,腾讯亦亮出新动作,宣布腾讯云TI平台已接入Llama 2、Falcon、Dolly等20多个主流模型,旨在打造行业大模型精选商店。
大厂们何以会有如此“整齐划一”的动作?
市场需求变化是一个因素。百度智能云AI与大数据平台总经理忻舟告诉数智前线,他们发现市场需求已逐渐进入深水区,仅文心一言一个模型,不能满足客户多样化需求,而如果能把一个平台做好,“会有更多的流量”。
业界观察,7月下旬,百度在对外表述中,已将原来的“文心千帆大模型平台”转变为“千帆大模型平台”,在做“去文心化”。
另一个现实因素是,大厂们单个项目报价普遍在千万元级别,闭源大模型暂时还没能有足够多的大项目落地。
此外,清华ChatGLM建立了有策略的、组合的商业模式,把小模型开源出去,吸引商机和生态,它的闭源大模型也可以为企业提供定制化服务。大模型厂商提供一个开源的但规模较小的大模型供大家使用,也是一种营销模式。
一位熟悉阿里云的资深人士也表示,他猜测,上述这些因素也是阿里开源两款大模型的重要原因之一。“走另外一条路试试看。”
而大模型变现的通路,并不只是模型本身。
数智前线获悉,华为在大模型上的考量,算力是重头之一。7月底到8月初,任正非就大模型有两次讲话,均与算力相关。
先是成立AI算力先遣队,由原煤矿军团团长邹志磊负责。任正非说,有4000个客户想要用华为昇腾平台去训练大模型。华为也将可能在10月成立15个小组去分别服务15个客户。之后,针对华为在《自然》杂志上发表的华为云盘古气象大模型的论文,任正非也谈及要“在新的淘金时代卖铲子”。
无独有偶,忻舟介绍,百度在大模型上的商业模式可分为两个层面。从文心一言这个大模型的角度讲,百度赚的是AI的钱。但千帆同时还是一个支持其他第三方模型的平台,本质上“还是云的思路,赚云的钱”。
此外,开源对生态建设也是百利而无一害。毕竟大模型被认为是智能时代的操作系统,而操作系统比拼的是生态,百度智能云AI平台副总经理李景秋认为,好的开源模型会极大吸引市场上创新公司关注大模型并参与其中,进而带来整个上下游服务生态的完善。
今年7月,阿里云也对外喊出“将促进中国大模型生态的繁荣作为首要目标”的口号。“这就类似于原来开源软件的模式,通过开源来吸引客户,建立产品的社区。”一位大模型领域资深人士表示。
该人士认为,无论国内国外、开源闭源,大模型的发布可能还会更多,具有通用基础能力的大模型,可能会集中到少数几个厂商,但具有行业细分的大模型,比较典型的像医疗、法律、教育,会有更多厂商去做。另外,基于大模型的能力做出来的应用级产品,会逐渐繁荣,形成一个新的生态和软件开发模式,“比如最近比较火的MetaGPT和ToolLLM”。
【本文由投资界合作伙伴微信公众号:数智前线授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。






清科创业(1945.HK)旗下
创业与投资资讯平台



 旗下微信矩阵:
旗下微信矩阵:
















