过去半年,向量数据库成为为数不多在AIGC光环下迅速走红的赛道,甚至有人将其视为AIGC成功的基石。7月4日,腾讯云也正式宣布推出向量数据库,成为大厂中首例,目前阿里云、亚马逊云等尚未释放出明确信号。
“谁*发布并不重要,重要的是谁有强大的资源能够将这件事情快速落实下去。”一位数据库产业观察者对钛媒体表示。对于大厂而言,是否要做一个独立的数据库还有待高层战略选择和布局节奏。但资本市场绝不会错过追逐任何一个风口。
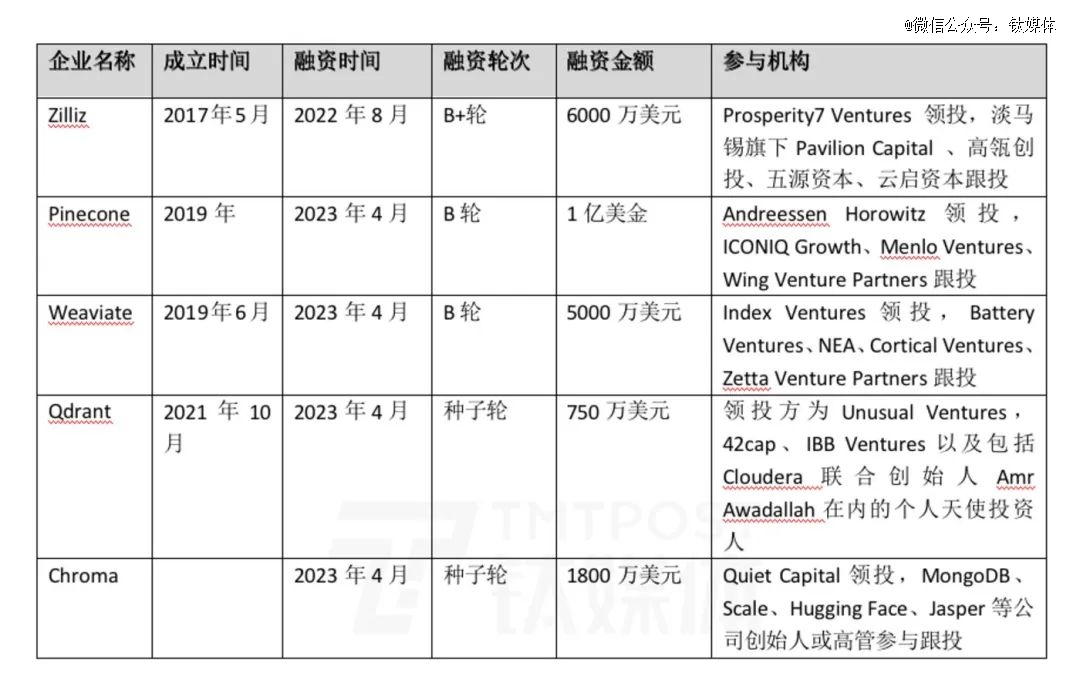
今年4月,Pinecone获得了a16z领投的1亿美元B轮融资,估值一度达到7.5亿美元。
作为OpenAI的合作方之一,Pinecone团队的创始人Liberty还是亚马逊AI实验室的*,创建了当前有名的机器学习平台SageMaker。而另一家同为OpenAI合作方、且估值超过5亿美金的团队,是来自中国的Zilliz。据钛媒体*获悉,近段时间,多家VC正在联络Zilliz试图给出新一轮融资,而这家企业距上一轮融资不足一年。
据钛媒体不完全统计,仅在2023年4月前后的一个月内,这个赛道已经相继有数家企业获得主流投资机构的投资,除了Pinecone外,还有Weaviate的5000万美元B轮融资、Qdrant的750万美元种子轮融资、Chroma的1800万美元种子轮融资……向量数据库无疑给了资本市场新的投资杠杆,但也有相关从业者预警,“想要做好需要积累,现在入局向量细分赛道已经晚了。”
向量数据库在大模型时代中展现出了巨大的商业机会。东北证券分析指出,向量数据库市场空间巨大,目前处于从0-1阶段。预测到2030年,全球向量数据库市场规模有望达到500亿美元,国内向量数据库市场规模有望超过600亿人民币。
不过,目前来看,这个赛道仍然充满变数。
一方面,应用广泛。即便传统数据库厂商不单独研发向量数据库,基本上也会选择主张支持原生的向量词嵌入和向量搜索引擎。对于那些缺乏向量检索功能的数据库,实现它可能也是时间早晚的问题。而对于有能力的大企业客户也完全可以基于开源引擎尝试使用,在此之前,许多互联网公司、AI大公司也早就在使用向量引擎。值得一提的是,最近这段时间就连老牌MongoDB也在其NoSQL数据库中增加向量搜索的方式进入到这股潮流。
另一方面,向量数据库依然有其落地的技术难点。例如相似性检索和计算复杂度的问题,对于Clickhouse的依赖性问题;作为一款面向AI应用的新型数据库(与现有的SQL稍做区分),它并没有替换已有的数据库,依然需要跟传统数据库搭配使用。
值得一提的是,AIGC大模型到来,实际上带来了新的场景应用点,这跟以往向量数据库厂商在探索的客户场景会有所不同。探索与创新,会显得十分重要。未来数据库能不能为上层的AI应用提供稳定、高性能的基础设施能力,才是重点考察方向。
目前业内也在寻求数据库与AIGC大模型的结合方式,例如阿里云今年最新迭代的云原生多模数据库Lindorm,也可以支持AIGC场景应用。
“能力是ready的,但没有人会非常有把握,因为现在AI的变化太快了,跟数据库的结合应该有更多的层次。”国内某数据库创业公司负责人表示,通过过去一段时间与客户的交流,现在正做的事情是将AI能力植入到其所倡导的Serverless HTAP数据库架构中。
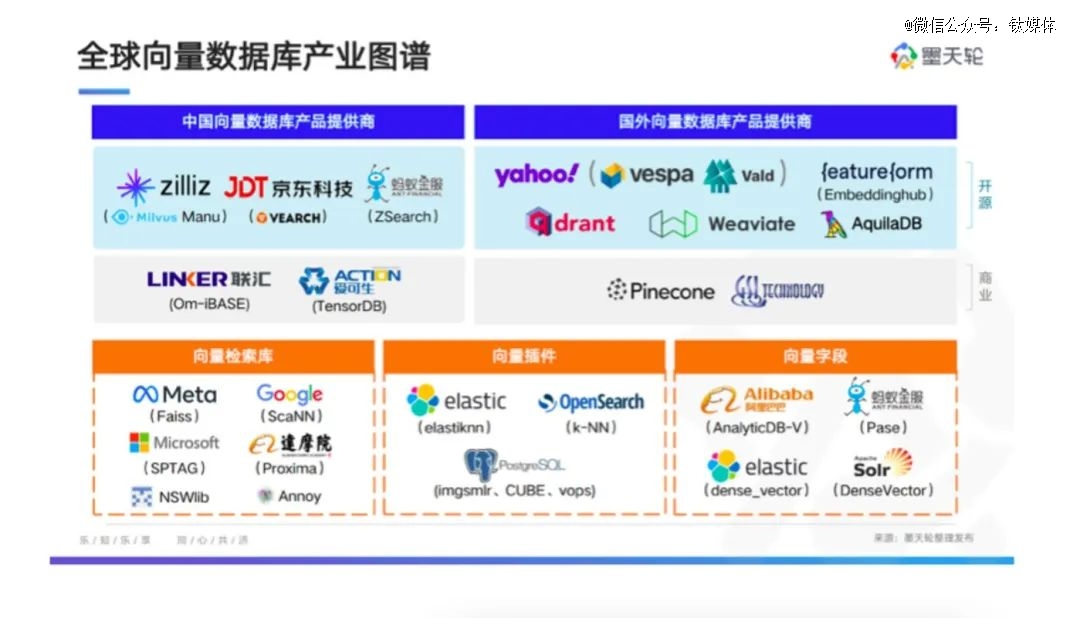
图片引用自摩天轮《中国数据库行业分析报告》,2022.10
结合墨天轮去年10月公布的全球数据库行业分析报告可以看到,其从技术维度将向量数据库产品进行了拆分:包括向量检索库、向量插件、向量字段、向量执行化引擎。这其实也在透露出一个问题:当下火的其实并不完全是向量数据库,而是在向量这一场景下的价值收益。
01 向量数据库怎么就火了
近期,许多具备大模型技术栈研发实力的企业,都会不约而同地提及“应用语言向量检索技术用于模型训练”。
在技术界,向量检索并不是一个新名词。但它的发展与人工智能浪潮的推动高度绑定。
向量,顾名思义Embedding,最开始的用于文本表达的词向量,到后来可用于表达图片、视频、语音等非结构化数据转化的深层语义,通过数据向量化可被计算机识别、使用,且在转化的过程中不丢失信息。一开始,向量技术也基本使用于互联网大公司的业务场景中。
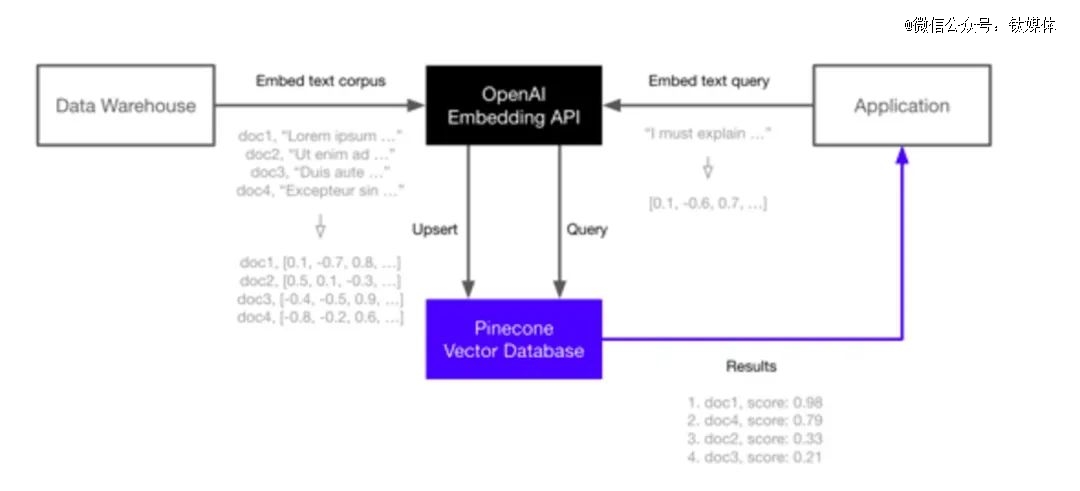
图片引用自Pinecone博客
例如,微软Bing搜索引擎,在2000年就曾宣布使用向量实现搜索引擎的增强,可处理2000多亿张网页的向量数据。在那个时代,这个数据已经非常庞大了,但在更多的工业界或实验室里,向量数据仍处于小规模验证的阶段。
真正的改变则来自于2017年前后,伴随深度学习在工业界的广泛落地,实际应用场景下的数据量级开始直线增加。这一年,FAIR研究人员开源了(FAISS,Facebook AI Similarity Search)AI向量相似性检索库,在十亿级数据集上创建了邻近搜索、且运行于GPU的k-selection算法。2020年7月,谷歌研究院开源了向量相似性搜索库ScaNN,提出新的数据集向量压缩技术,以提高向量检索的准确性。
实际上,在此期间,国内的互联网公司也没闲着,据说阿里巴巴自研了Proxima,对于更多的企业,包括创业厂商在内,也会使用向量相似性检索技术的相关开源组件如Faiss、Nmslib和Annoy等ANN库,京东零售基于Faiss的Vearch也已经在各自规模化业务场景中投入使用。
创业公司Zilliz从2018年开始布局做向量数据库,2019年开源了Milvus,单独作为一个品类进行研发创新。其做法比较明确:开源Milvus向量数据库,持续运营积累大量社区开发者使用;在商业化方面,推出云端全托管数据库服务Zilliz Cloud,并与Milvus形成插件化集成,与国产大模型进行对接。
不过,不同于2017年前后在行业风口和资本热钱影响下成立的一批AI公司,一开始就瞄准向量数据库创业赛道的企业其实寥寥无几。即便Zilliz也并非是从创业之初锚定向量数据库——Zilliz创始人星爵在去年9月与钛媒体交流时曾解释:“AI时代,数据处理的类型和计算体系架构都发生了较大变化,但当时团队对最终产品形态是什么,并不是很清晰。不断交流的过程中,我们意识到企业对海量非结构化数据管理的需求。”
总结起来,在向量数据库的发展过程中,技术进展和创新起到了重要的推动作用。
首先在数据层面,向量作为一个新型数据处理单元,其数据量达到了一定规模,需要一个专用的管理系统,对管理的复杂度如分布式、高可用性、数据的一致性和备份等要求也越来越高。
其次,数据库系统的研究者和工程师们不断改进和优化向量数据库的存储引擎、索引结构和查询算法,提高了向量数据的存储效率和查询性能。
此外,随着硬件技术的发展,如GPU、FPGA、ARM架构芯片的应用,也为向量数据库的性能提升带来了新的机会。
这三点因素共同促使了向量数据库系统的诞生——想要高效处理这些海量的向量数据,就需要更细分、更专业的数据基础设施,为向量构建专门的数据库处理系统。
02 现阶段,客户有必要替换吗?
从产品层面讲,如果传统数据库厂商不单独研发向量数据库,那么基本上会主张支持原生的向量词嵌入和向量搜索引擎。
向量数据库市场的阵营在ChatGPT影响之前就已经在形成分化,既包括提供开源组件的Milvus、Vald、Weaviate、Qdrant、Vaspa、Vearch、AquilaDB、Marqo,到商业化服务产品Pinecone,再到大厂谷歌推出的Vertex AI匹配引擎,数据库厂商Elastic和Redis基于自身提供的向量检索功能等等。
这其实也表明了当前向量数据库市场存在的两种路线:一个是基于分析数据库的向量化执行引擎,英文是Vectorization,这是学术界2013年提出的名词,如Clickhouse、Spark引擎,是一种新型的执行方式,用于处理传统的结构化数据如表单等,更多的是结构化数据分析数据里面做并行执行的一种方式,在新型的处理芯片上进行处理。
另一个则是推出向量数据库(Vector Database),本质上处理的是AI领域的一类新型数据类型,例如对多模数据的处理,相比其他的向量检索技术在检索速度和精准性上都有了一个很高的提升。
后者的做法也基本在几家主流云厂商如亚马逊云、阿里云上能够看到,而这些云平台应用市场也会提供给这些第三方向量数据库企业进行托管。例如,阿里云开发的内存数据库Tair,在兼容Redis生态的同时,也具备向量检索能力,实现缓存+向量二合一,已经投入在电商等场景。
“如果你看好AI,你就可以看好向量数据库。”2023年的大模型大火一段时间后,腾讯云数据库团队最终明确了这样一个逻辑。
腾讯云会更倾向于倡导向量数据库“专库专用”的理念,并且认可这样一个趋势。腾讯云正式发布向量数据库时,腾讯云数据库副总经理罗云这样对钛媒体解释:“向量检索技术确实不是今天才有,在此之前有像基于Faiss库的单机检索引擎,也有已有数据库上外挂插件的形态,还有的则是具备Purpose-built的独立向量数据库。”
在他看来,由于向量检索是一个极消耗CPU和内存资源的工作,当支撑的业务负载越来越大之后,之前这种传统的插件形式就会面临一定的挑战。而独立向量数据库可以让用户更好地精细化管理大模型训练时的资源成本和时间问题。
此外,还由于客户对私域数据的保护,不会放在共有云的大模型平台上进行训练,而是更愿意将私域数据存储在向量数据库中,当需要推理时就会将一部分信息传递给大模型作推理。云厂商提供的数据服务会更有竞争力。
据罗云所述,腾讯云自研的分布式向量数据库核心引擎Olama,原名ElasticFaiss,最早于2019年4月进行孵化,过去几年,Olama对开源架构技术点持续优化,以支撑越来越多的算法库。
目前,处在探索期的向量数据库依然充满挑战:一是数据存储和索引。
由于向量数据通常具有高维度和大规模的特点,传统的存储和索引方法无法满足其高效查询的需求。二是查询性能和计算复杂度。由于向量数据的特殊性质,相似性搜索和向量操作往往需要进行大量的计算和比较。三是数据质量和准确性。向量数据中可能存在噪声、缺失值和异常值等问题,这些问题会对数据的查询和分析结果产生不良影响等。
相较于大模型的高调火热,向量数据库仍然靠近底层,并没有达到真正意义上的全民皆知,向量数据库更多时候是需要集成到其他平台或云上被销售。
而从需求端看,过去,向量检索还主要聚焦于机器学习和数据挖掘领域,通过高效的数据存储和查询工具,使得相似性搜索和聚类分析成为可能。在推荐系统中,向量数据库助力个性化推荐,根据用户兴趣和商品相似性,呈现给用户最贴切的推荐结果。
如今,在ChatGPT爆火之后,前来咨询向量数据库的客户也络绎不绝,并且涌现出了一批新的中小型开发者。Zilliz团队的一个直观感受是,目前大家主要的竞争会集中在产品功能设计和易用性上。如Midjourey只有11人团队,这类小团队用户业务更加聚焦于大模型应用,这与此前大数据量的互联网B端用户有明显需求的不同。
一位售前人员解释,还是要根据客户的业务属性,需要的数据库系统是否解决的是面向AI应用的部分。
无论怎样,外界正在意识到向量数据库作为一种新型数据库存在的价值。不过,理解大模型只是AI的其中一种形态,泛化能力变强,场景通用性也更强,以大模型助力AI落地变得更顺畅的过程中,还有很多可优化空间。
【本文由投资界合作伙伴微信公众号:钛媒体授权发布,本平台仅提供信息存储服务。】如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。






清科创业(1945.HK)旗下
创业与投资资讯平台



 旗下微信矩阵:
旗下微信矩阵:
















