[未掲載分] 「除算が遅い」の補足 (4)
今回も「除算が遅い」、「除算の高速化」などのキーワードで検索サイトからお越しいただいている方々への対応記事となります。
前話で、
レジスタ数に余裕があるか否かでアプリの実行効率が変わってくる
旨を述べた。
レジスタの本数うんぬんという例えでは判り難いというヒトもいることだろう。
作業人数が足りているか人手不足かといったところだ。
例えば、何かの製造作業に没頭しているとしよう。ほかの部門で人手不足が生じたので手伝うようにと指令された場合、現在行っている作業を中断してほかの部門の手伝いに向かう。
やがて、お手伝いが終わったところで本来の作業に戻る。然るに、お手伝いに関わっていた分、その前に関わっていた作業は遅れてしまう。
今回は除算そのものの話ではなく、前話の続き・・・
お知らせ
活動休止にともない、この記事を事前に予約投稿してあります。
トップ記事の固定を目的としています
空きレジスタうんぬんといった話し入る前に頭の体操を。
依存関係を考えずにアプリの高速化を考えると遠回りである。
並列に実行できる、できない
を練ることで問題解消のカギとなるハズ。
まず、単純な2つの式で考えてみよう。


それぞれは独立している、つまり
依存関係が無い。
もし、2番目の式が D=E+F ではなく D=A + F ならば、B÷C の結果が出るのを待ってから A + F に着手することになる。
別の表現を用いれば、
作業を分担できるか否か
である。前後の作業に関連性が無い作業なら同時刻に実行しても差し支えない。
昨今のCPU は複数の実行ユニットを備えている。前後の命令が独立したものであれば、複数の命令を同時に実行できる。
アプリを作ってみたいと思い立ち、書籍やWebサイトに載っているソースコードを打ち込んで満足してしまうヒトもいることだろう。
綺麗なソースコードを学ぶだけでなく、ハードウェアの特性を理解しながら進むことで良い結果が導き出されるかも・・・
さてさて、本題の空きレジスタうんぬんの話。
前話でも述べた通り、64ビット版の CPUでは汎用レジスタの幅が64ビットに拡張されたほか、本数も倍の16本に増えた。
64ビット版の CPU が登場する前、1999年ごろ登場した Pentium iii で XMM レジスタが8本追加された。XMM レジスタといってもピンと来ないヒトもいるだろう。SSE 命令を扱うための専用レジスタである。
XMM レジスタはベクトル演算を得意としており、汎用レジスタの4つ分にあたる128ビット幅。昨今さらに上位128ビット分が拡張され、256ビット幅を持つ YMM レジスタが拡張されている。XMM レジスタが SSE 命令を扱うために増強されたとすれば、YMM レジスタは AVX 命令を扱うための増強である・・・
ところで、その前にレジスタが追加されていたのではないかと疑問に思うヒトもいるだろうから補足。
1990年代、PC で 音声や動画を楽しみたいという声が高まった。マルチメディア処理を円滑にとの目的で1997年頃、MMX 命令を処理する機能が追加された CPU が登場した。MMX 命令対応の Pentium と後継機の Pentium II がリリースされた。前者はマザーボードが対応していれば、今までのPentium と差し替えて使うことができた CPU である。
後者は物理的な互換性が無く、某家庭用ゲーム機のゲームカートリッジのような形状をしていた、それまでの CPU 装着部がソケットなのに対し、スロットと呼ばれた。

初期の Pentium iii もこの形状。
スロット形CPUを装着するにはコツがあり、PC 関連の雑誌でも取り上げられていました。この頃、PC の自作が流行しいましたが、CPU が奥深くまで挿さっていない等でPC が起動しないといったトラブルに遭ったヒトもいるようです。

また、スロット形CPUはソケット状のCPUと比べ大型で、PC ケース内の通気性という面で不利でした。後からソケット状の Pentium iii がリリースされ、一般の職場や家庭向けのデスクトップ PC ではスロット形CPUを見かけなくなりました・・・
MMX 命令を実行できるように拡張された際、64ビット幅のレジスタが8本増設された!?!?
といった誤解のもととなる記述も見受けられます。実際のところ、増設ではなく転用。
1993年頃登場した、Pentium から FPU ( 浮動小数点演算処理装置 ) が標準搭載されました。FPU はコプロセッサや NDP 、NPX とも呼ばれていましたが、文字通りの演算専用の装置。それまでは後付けであったり、廉価版では省かれていました。
特定の科学分野等を除き、FPU はほとんど活用されていませんでした。それを活かす方向で MMX 命令を実行できるように施されました。
FPU は80ビット幅のスタック8本で構成されています。これを64ビット幅の整数演算レジスタ8本として割り当てられたのです。つまり、専用レジスタの新設ではなく既存リソースの転用です。
裏を返せば、FPU と MMX は排他的に利用せねばなりません。浮動小数点演算とMMX 命令は同時に実行できないほか、当初は切り替え手続きも迅速ではありませんでした。
待ち時間は汎用レジスタに数値をロードやストアする命令の数十倍とされていました。
排他的や切り替えといった表現は難しいかも。一人二役でライブに出演するような事を想定してみましょう。最初の役を演じ終り次の役へ移る際、衣装を着替えたりメイクを変えるなどの準備に手間取ってしまう。その分周囲は待たされてしまうようなものです。
後々CPU が進化するにつれ、FPU と MMX の切り替えに要する待ち時間も短縮されました。昨今のCPU では データのロードやストアの待ち時間とほぼ同等で切り替えることが可能です。
64ビット版の Windows では FPU や MMX がサポートされていません。
誤解の無いように加えておくと、ほかのアプリと実行権を切り替える際、現状の値を保存、復元する仕組みが削減されたのが原因と言われています。
マルチタスクの環境において、複数のアプリが同時に起動してます。アプリの実行権切り替えは OS が行います。アプリの実行権が一時ほかに移り、次に実行権が巡ってきた時にレジスタやスタックの内容が一致する保障されません。
64ビット版の Windows で 32ビット版を実行する際には保存、復元する仕組みが働くように工夫が施されています。過去に作成されたアプリやソースコードを活用できるようにとの配慮かもしれません。
この辺から、FPU や MMX がハードウェア的に動いているのが判ります。そのことから、64ビット版のアプリを組む際、レジスタやスタック操作の命令を加えることも可能ではないかと思えてきます。
独自にゴニョゴニョと試したところ、64ビット版の Windows で 64ビット版を実行する際でも FPU や MMX の内容を保存、復元する仕組みは残されていました。
とはいえ、時期は明言されてはいませんが いずれ FPU は 廃止されるようです。よって、今後は FPU や MMX に依存したアプリを組むのは避けるべきでしょう・・・
XMM レジスタが増設されたことにより、ひと命令で32ビット幅の単精度浮動小数点値を最大4組同時に演算できるようになりました。しかし、初期のSSE 命令体系ではでは物足りず、SSE2 ~ SSE4.2 へと序々に拡がってきました。
C/C++ 言語で浮動小数を扱いたい場合、一般的には float や double といった変数の型を用いる。前者が単精度浮動小数点数、後者は倍精度浮動小数。単精度は32ビット、倍精度は64ビットの幅。
細かく言えば、80ビット幅の倍精度や128ビット幅の四倍精度、八倍精度などもあります。が、これを記している時点で一般的ではないので省きます。
ゲーム等で大雑把に計算で良いならば単精度でも足りるでしょう。が、映像、画像や音などを扱うアプリではなるべく高い精度の演算結果を得たくなる。なぜなら、演算の精度が低いほど不鮮明、ノイズが混じるなど残念な処理結果に繋がるから。
結果重視ならば、単精度よりも倍精度で演算したいところです。しかし、初期のSSE では扱えませんでした。
実際に使い勝手が良くなったと感じたのは SSE2 以降。西暦2000年暮れ頃に登場した Pentium 4 で SSE2 命令が実装、つまり、利用可能になりました。
SSE2 では倍精度を2組、さらに 32ビット幅の整数4組もしくは64ビット幅の整数2組同時に扱う等の命令が追加されました。その後のSSE3 や SSE4.xx は水平加算や文字列処理に特化した補強が加わりました。
遡って、整数の加算や乗算はSSE が実装される前の MMX 命令で対応することもできました。ただし、MMX で乗算を施す場合、16ビット幅を基本となっていることもあり、SSE2 でひとつの命令で済むのに比べ、上位ビットと下位ビットを掛け合わせて足すといった具合で面倒でした。
ちなみに、SSE2 から XMM レジスタを用いて倍精度浮動小数の四則演算が可能となりました。SSE2 から SSE4.2 に至るまで、整数の除算は実装されていません。
XMM レジスタや SSE2 命令 が追加されたことにより
・自由に使えるレジスタ数が増えたという利点だけでなく、
・同じ待ち時間で2倍もしくは4倍の演算をこなせるようになった点も大きい。
これを書いている時点で、
FPU のスタックを介して倍精度の乗算や除算を行うクロック数とXMM レジスタを用いて2組の倍精度演算を行うクロック数はほぼ同じ。
そろそろ、この辺で前話と結びつけていきましょう。
32ビット版のアプリでレジスタの本数が足りず、速度低下に陥いりそうな箇所はどうしたら良いだろうか???
汎用レジスタはループ回数や数値のロード、ストアする場所、演算はXMM レジスタに任せることを意図したソースコードに書き換えるのが解消のカギとなる。
まずはお手軽なところから。SSE2 命令を積極的にコンパイラに任せてしまう方法が楽。なお、開発環境として Microsoft の Visual Studio 、C/C++ 言語の利用を想定している。
アプリをビルドする際、
/arch:SSE2 オプションを指定することで可能なかぎりSSE2 命令に置き換わる。
プロジェクトの 「プロパティページ」 ダイアログ ボックスを開く。
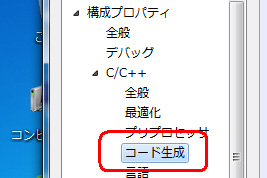
ダイアログボックスの左側ペイン「構成プロパティ」、「C/C++」 フォルダーをクリック。
「コード生成」プロパティページをクリック。
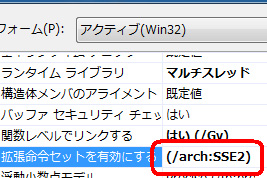
ダイアログボックスの右側、「拡張命令セットを有効にする」をクリックし、
ストリームSIMD 拡張機能 2 /arch:SSE2を選択する。
コンパイラに丸投げともいえるが、ビルド時に出力されたアセンブリー言語ファイルを眺めればほどよい感じで最適化されている。
ソースコードで float や double など浮動小数の演算を意図した箇所はおおむね XMM レジスタが使われるように置き換えられる・・・
ところで、
/arch:○○○ オプションを指定しなかった場合はどうなるの???
32ビット環境向で普遍的なソースコードを書きビルドした場合、汎用レジスタと FPU を介したコードが生成されてしまう。登場したての32ビット版 CPU でも動作するようなアプリが生成される。もちろん、古い世代の CPU でも実行できるという点では感心する・・・
もうひとつ。64ビット環境では /arch:SSE2 の指定は不要。少し前の部分で「64ビット版の アプリでは FPU や MMX がサポートされない」と書いた。
浮動小数を扱う演算はXMM レジスタを介して処理することがデフォルトとなっている。C/C++言語で、float や double などの浮動小数の型の変数を使った部分も自動的に置き換わる。
長くなりましたので今回はこの辺で・・・
前話で、
レジスタ数に余裕があるか否かでアプリの実行効率が変わってくる
旨を述べた。
レジスタの本数うんぬんという例えでは判り難いというヒトもいることだろう。
作業人数が足りているか人手不足かといったところだ。
例えば、何かの製造作業に没頭しているとしよう。ほかの部門で人手不足が生じたので手伝うようにと指令された場合、現在行っている作業を中断してほかの部門の手伝いに向かう。
やがて、お手伝いが終わったところで本来の作業に戻る。然るに、お手伝いに関わっていた分、その前に関わっていた作業は遅れてしまう。
今回は除算そのものの話ではなく、前話の続き・・・
お知らせ
活動休止にともない、この記事を事前に予約投稿してあります。
トップ記事の固定を目的としています
空きレジスタうんぬんといった話し入る前に頭の体操を。
依存関係を考えずにアプリの高速化を考えると遠回りである。
並列に実行できる、できない
を練ることで問題解消のカギとなるハズ。
まず、単純な2つの式で考えてみよう。


それぞれは独立している、つまり
依存関係が無い。
もし、2番目の式が D=E+F ではなく D=A + F ならば、B÷C の結果が出るのを待ってから A + F に着手することになる。
別の表現を用いれば、
作業を分担できるか否か
である。前後の作業に関連性が無い作業なら同時刻に実行しても差し支えない。
昨今のCPU は複数の実行ユニットを備えている。前後の命令が独立したものであれば、複数の命令を同時に実行できる。
アプリを作ってみたいと思い立ち、書籍やWebサイトに載っているソースコードを打ち込んで満足してしまうヒトもいることだろう。
綺麗なソースコードを学ぶだけでなく、ハードウェアの特性を理解しながら進むことで良い結果が導き出されるかも・・・
さてさて、本題の空きレジスタうんぬんの話。
前話でも述べた通り、64ビット版の CPUでは汎用レジスタの幅が64ビットに拡張されたほか、本数も倍の16本に増えた。
64ビット版の CPU が登場する前、1999年ごろ登場した Pentium iii で XMM レジスタが8本追加された。XMM レジスタといってもピンと来ないヒトもいるだろう。SSE 命令を扱うための専用レジスタである。
XMM レジスタはベクトル演算を得意としており、汎用レジスタの4つ分にあたる128ビット幅。昨今さらに上位128ビット分が拡張され、256ビット幅を持つ YMM レジスタが拡張されている。XMM レジスタが SSE 命令を扱うために増強されたとすれば、YMM レジスタは AVX 命令を扱うための増強である・・・
ところで、その前にレジスタが追加されていたのではないかと疑問に思うヒトもいるだろうから補足。
1990年代、PC で 音声や動画を楽しみたいという声が高まった。マルチメディア処理を円滑にとの目的で1997年頃、MMX 命令を処理する機能が追加された CPU が登場した。MMX 命令対応の Pentium と後継機の Pentium II がリリースされた。前者はマザーボードが対応していれば、今までのPentium と差し替えて使うことができた CPU である。
後者は物理的な互換性が無く、某家庭用ゲーム機のゲームカートリッジのような形状をしていた、それまでの CPU 装着部がソケットなのに対し、スロットと呼ばれた。

初期の Pentium iii もこの形状。
スロット形CPUを装着するにはコツがあり、PC 関連の雑誌でも取り上げられていました。この頃、PC の自作が流行しいましたが、CPU が奥深くまで挿さっていない等でPC が起動しないといったトラブルに遭ったヒトもいるようです。

また、スロット形CPUはソケット状のCPUと比べ大型で、PC ケース内の通気性という面で不利でした。後からソケット状の Pentium iii がリリースされ、一般の職場や家庭向けのデスクトップ PC ではスロット形CPUを見かけなくなりました・・・
MMX 命令を実行できるように拡張された際、64ビット幅のレジスタが8本増設された!?!?
といった誤解のもととなる記述も見受けられます。実際のところ、増設ではなく転用。
1993年頃登場した、Pentium から FPU ( 浮動小数点演算処理装置 ) が標準搭載されました。FPU はコプロセッサや NDP 、NPX とも呼ばれていましたが、文字通りの演算専用の装置。それまでは後付けであったり、廉価版では省かれていました。
特定の科学分野等を除き、FPU はほとんど活用されていませんでした。それを活かす方向で MMX 命令を実行できるように施されました。
FPU は80ビット幅のスタック8本で構成されています。これを64ビット幅の整数演算レジスタ8本として割り当てられたのです。つまり、専用レジスタの新設ではなく既存リソースの転用です。
裏を返せば、FPU と MMX は排他的に利用せねばなりません。浮動小数点演算とMMX 命令は同時に実行できないほか、当初は切り替え手続きも迅速ではありませんでした。
待ち時間は汎用レジスタに数値をロードやストアする命令の数十倍とされていました。
排他的や切り替えといった表現は難しいかも。一人二役でライブに出演するような事を想定してみましょう。最初の役を演じ終り次の役へ移る際、衣装を着替えたりメイクを変えるなどの準備に手間取ってしまう。その分周囲は待たされてしまうようなものです。
後々CPU が進化するにつれ、FPU と MMX の切り替えに要する待ち時間も短縮されました。昨今のCPU では データのロードやストアの待ち時間とほぼ同等で切り替えることが可能です。
64ビット版の Windows では FPU や MMX がサポートされていません。
誤解の無いように加えておくと、ほかのアプリと実行権を切り替える際、現状の値を保存、復元する仕組みが削減されたのが原因と言われています。
マルチタスクの環境において、複数のアプリが同時に起動してます。アプリの実行権切り替えは OS が行います。アプリの実行権が一時ほかに移り、次に実行権が巡ってきた時にレジスタやスタックの内容が一致する保障されません。
64ビット版の Windows で 32ビット版を実行する際には保存、復元する仕組みが働くように工夫が施されています。過去に作成されたアプリやソースコードを活用できるようにとの配慮かもしれません。
この辺から、FPU や MMX がハードウェア的に動いているのが判ります。そのことから、64ビット版のアプリを組む際、レジスタやスタック操作の命令を加えることも可能ではないかと思えてきます。
独自にゴニョゴニョと試したところ、64ビット版の Windows で 64ビット版を実行する際でも FPU や MMX の内容を保存、復元する仕組みは残されていました。
とはいえ、時期は明言されてはいませんが いずれ FPU は 廃止されるようです。よって、今後は FPU や MMX に依存したアプリを組むのは避けるべきでしょう・・・
XMM レジスタが増設されたことにより、ひと命令で32ビット幅の単精度浮動小数点値を最大4組同時に演算できるようになりました。しかし、初期のSSE 命令体系ではでは物足りず、SSE2 ~ SSE4.2 へと序々に拡がってきました。
C/C++ 言語で浮動小数を扱いたい場合、一般的には float や double といった変数の型を用いる。前者が単精度浮動小数点数、後者は倍精度浮動小数。単精度は32ビット、倍精度は64ビットの幅。
細かく言えば、80ビット幅の倍精度や128ビット幅の四倍精度、八倍精度などもあります。が、これを記している時点で一般的ではないので省きます。
ゲーム等で大雑把に計算で良いならば単精度でも足りるでしょう。が、映像、画像や音などを扱うアプリではなるべく高い精度の演算結果を得たくなる。なぜなら、演算の精度が低いほど不鮮明、ノイズが混じるなど残念な処理結果に繋がるから。
結果重視ならば、単精度よりも倍精度で演算したいところです。しかし、初期のSSE では扱えませんでした。
実際に使い勝手が良くなったと感じたのは SSE2 以降。西暦2000年暮れ頃に登場した Pentium 4 で SSE2 命令が実装、つまり、利用可能になりました。
SSE2 では倍精度を2組、さらに 32ビット幅の整数4組もしくは64ビット幅の整数2組同時に扱う等の命令が追加されました。その後のSSE3 や SSE4.xx は水平加算や文字列処理に特化した補強が加わりました。
遡って、整数の加算や乗算はSSE が実装される前の MMX 命令で対応することもできました。ただし、MMX で乗算を施す場合、16ビット幅を基本となっていることもあり、SSE2 でひとつの命令で済むのに比べ、上位ビットと下位ビットを掛け合わせて足すといった具合で面倒でした。
ちなみに、SSE2 から XMM レジスタを用いて倍精度浮動小数の四則演算が可能となりました。SSE2 から SSE4.2 に至るまで、整数の除算は実装されていません。
XMM レジスタや SSE2 命令 が追加されたことにより
・自由に使えるレジスタ数が増えたという利点だけでなく、
・同じ待ち時間で2倍もしくは4倍の演算をこなせるようになった点も大きい。
これを書いている時点で、
FPU のスタックを介して倍精度の乗算や除算を行うクロック数とXMM レジスタを用いて2組の倍精度演算を行うクロック数はほぼ同じ。
そろそろ、この辺で前話と結びつけていきましょう。
32ビット版のアプリでレジスタの本数が足りず、速度低下に陥いりそうな箇所はどうしたら良いだろうか???
汎用レジスタはループ回数や数値のロード、ストアする場所、演算はXMM レジスタに任せることを意図したソースコードに書き換えるのが解消のカギとなる。
まずはお手軽なところから。SSE2 命令を積極的にコンパイラに任せてしまう方法が楽。なお、開発環境として Microsoft の Visual Studio 、C/C++ 言語の利用を想定している。
アプリをビルドする際、
/arch:SSE2 オプションを指定することで可能なかぎりSSE2 命令に置き換わる。
プロジェクトの 「プロパティページ」 ダイアログ ボックスを開く。

ダイアログボックスの左側ペイン「構成プロパティ」、「C/C++」 フォルダーをクリック。
「コード生成」プロパティページをクリック。

ダイアログボックスの右側、「拡張命令セットを有効にする」をクリックし、
ストリームSIMD 拡張機能 2 /arch:SSE2を選択する。
コンパイラに丸投げともいえるが、ビルド時に出力されたアセンブリー言語ファイルを眺めればほどよい感じで最適化されている。
ソースコードで float や double など浮動小数の演算を意図した箇所はおおむね XMM レジスタが使われるように置き換えられる・・・
ところで、
/arch:○○○ オプションを指定しなかった場合はどうなるの???
32ビット環境向で普遍的なソースコードを書きビルドした場合、汎用レジスタと FPU を介したコードが生成されてしまう。登場したての32ビット版 CPU でも動作するようなアプリが生成される。もちろん、古い世代の CPU でも実行できるという点では感心する・・・
もうひとつ。64ビット環境では /arch:SSE2 の指定は不要。少し前の部分で「64ビット版の アプリでは FPU や MMX がサポートされない」と書いた。
浮動小数を扱う演算はXMM レジスタを介して処理することがデフォルトとなっている。C/C++言語で、float や double などの浮動小数の型の変数を使った部分も自動的に置き換わる。
長くなりましたので今回はこの辺で・・・
本日も最後までご覧いただきありがとうございます。
「つまらなかった」「判り辛った」という方もご遠慮なくコメント欄へどうぞ
