[未掲載分] 「除算が遅い」の補足 (9)
「除算が遅い」の補足 (8)の続き。多くのヒトにとって除算が速い遅いといった話題は興味が沸かないことだろう。
例えば、音遊びに使うアプリを作るとしよう。これは、音とび ( クリッピングが生じた音声データ ) を修正するために組んだアプリである。
もとの音データは整数値で収納されている。アプリはそれを読み出し、乗算・除算・三角関数などを通して処理して保存する。
アプリを使う側の視点で考えてみよう。演算が遅いということは待ち時間が増える。画像や音を編集するアプリを利用する際、多かれ少なかれ待ち時間が発生する。多く待たされることはストレスにつながる。数十秒で終わるのか、はたまた、一時間近く待たされるのか・・・
お知らせ
活動休止にともない、この記事を事前に予約投稿してあります。
トップ記事の固定を目的としています
※ これを下書きしたのは2012年夏の終わり頃です。
ご覧いただいている時期によっては状況が異なっている可能性があります。
下書きした頃の環境は、OS - Microsoft Windows 7、開発環境 - Visual Studio 2008 , C/C++ 言語。
Intel 80386 ( i386 ) の流れを汲む Core i7 や Pentium や Atom 等 の CPU もしくは互換品を前提としています。
予め述べておくが、
C/C++ 言語でいうところの変数の型や型変換など、基礎的な事柄の理解が曖昧なままここに辿りついたヒトもいることだろう。この先の内容を飲み込むのは辛いと思われる。ほかのプログラミング言語を用いるにしろ、そのようなヒトは除算の高速化うんぬんの前に基礎的な事柄を習得した後、再度ご覧頂ければ幸いである・・・
少しおさらい。
「除算が遅い」の補足 (6)で2組分の除算を行える~~~待ち時間はほぼ一緒。と述べた。
並列に実行できる、できないに関して手順を練り直すことで、さらなる高速化を目指せる。
なぜ XMM レジスタの明示的な利用するのかについては、「除算が遅い」の補足 (3)や「除算が遅い」の補足 (4)で綴ったように、
レジスタ数に余裕があるか否かで実行速度が左右されるからである。
※ 汎用レジスタは標準装備 ( もともと備わっていた )、XMM レジスタは後から追加された。
32ビット版の OS で実行するアプリを作成した際、空きレジスタの不足を補うようなコードが生成されることがあり、速度低下の要因になる。64ビット版の OS 上で32ビット版 のアプリを実行することは可能であるが、これは解消されない。
つぎに、64ビット版の OS 向けにアプリを作成した場合、32ビット版に比べ汎用レジスタ数に余裕がある。汎用レジスタで64ビット数値を直接扱える。したがって、XMM レジスタを積極的にメリットが薄いように感じてしまう。
64ビット版のアプリでは FPU を介した演算がサポートされない。西暦1993年頃に登場した Pentium から FPU ( 浮動小数点演算処理装置 ) が標準搭載されるようになった。そのほか、XMM レジスタでの演算は、FPU を介するのに比べ、同時に2組分の演算をこなせるので待ち時間を減らすことに繋がる。FPU の内部での演算精度が 80ビットである点は魅力的ではあるが・・・
しかし、前回綴ったように、SSE2 命令体系の中に整数の除算が含まれていない。
誤解が生じるといけないので、「命令が備わっていない。」と表現した方が適切だろうか。ハードウェア内部には除算を行う回路が備わっていても、それを呼び出す命令が存在しない。
もちろん、ソフトウェアレベルでの代替は可能である。しかし、「除算が遅い」の補足 (1)や「除算が遅い」の補足 (3)で触れたように、ソフトウェアレベルでの代替処理に速さ求めても仕方がない。
その後、SSE4.2 に至るまで整数の除算命令は追加されなかった。では、整数の除算に関して諦めるしかないのだろうか?
前回、XMM レジスタで倍精度浮動小数点値と 32 ビット整数値、もしくはその逆の変換が可能とヒントを載せた。
C/C++ 言語でいうところの型変換 ( キャスト) が判っていれば理解し易いハズ。
いま、どの型で演算しようとしているのか???等の基礎が曖昧なままアプリ作成を続けているヒトもいることだろう。昨今はプログラミングに親しみやすいようにとの計らいで、その辺を深入りせずともアプリを組めるようになってきた。とはいえ、上の段階に歩を進めようとした際に戸惑うことがないよう、基礎固めは重要・・・
この記事は Core i7 や Pentium や Atom 等 の Intel 80386 ( i386 ) の流れを汲む CPU を前提にしている。
一般的な PC の CPU は自動車でいうところのエンジンに該当する。西暦1993年頃に登場した Pentium から FPU が標準搭載され浮動小数点数 ( 実数 )を直接扱えるようになった。それまでは 別売りの FPU を追加するか、FPU を介しないソフトウェアによる代替で処理するようなアプリを組む必要があった。
もっと遡れば、CPU が直接扱えるのは 整数に限られていた時期もある。諸説あるが、電子計算が行われるようになったのは西暦1946年頃と言われている。現在用いられている単精度や倍精度浮動小数点数演算の標準化が行われたのは西暦1985年ごろ・・・
整数しか扱えない不便さは想像し難いだろうか。
例えば、本体価格10円、そこに5%の税金が乗るとしよう。人間の頭では一個10.5円と考えることができる。
いちばん小さい通貨の単位が1円であるならば、切り捨てて10円、切り上げて11円。前者では売る側が0.5円を負担、後者なら買う側が多く支払うことになる。どこか不公平。
もちろん、毎回2個一組での売買に定め、値段は21円に設定するなどの策も考えられるのだが・・・
XMM レジスタを用いて整数から倍精度浮動小数点値に変換する、または、その逆の命令 (倍精度浮動小数点値から整数に変換する ) を知りたい場合、
・IA-32 インテル アーキテクチャ ソフトウェア・デベロッパーズ・マニュアルや
・インテル エクステンデッド・メモリ64 テクノロジ・ソフトウェア・デベロッパーズ・ガイド等の書物が役立つ。もちろん無料。それら資料の入手に関しては過去記事車輪の再発明 (8)をご覧あれ。
「変換」は「convert」「conversion」「transformation」。IA-32 インテル アーキテクチャ ソフトウェア・デベロッパーズ・マニュアルは4巻。そのうち、中巻A:命令セット・リファレンスA-M。おそらく、「conv~~」「cvt~~」の項を眺めると何か見つかる。
CPU が直接解釈できるような機械語コードやCVT○○○といった擬似コードを覚えるのは苦労する。
C/C++ 言語でアプリを作成するなら組み込み関数を利用する。開発環境が Visual Studio だとすれば、「_mm_cvtepi32_pd」 と 「_mm_cvtpd_epi32」 の組み込み関数を用いることが可能。前者が整数から倍精度浮動小数への変換、後者はその逆。
「_mm_ ○△□」といった関数名を覚えるのが面倒!?!?!?
それに関しては「除算が遅い」の補足 (6)で触れたように「_mm_ ○△□ _pd」といった組み込み関数は「○△□」の部分が掛け算なら 「MUL」 、 割り算なら「DIV」と理解できる。同様に、数値を変換したい際に用いる組み込み関数の名は
「_mm_cvt」、「変換もと変数の型」、アンダースコア ( 下線 )、「変換される変数の型」の順に並んでいると理解できるハズ。
例えば、「_mm_cvtsd_si32」という組み込み関数であれば、倍精度浮動小数点値を符号付き 32 ビット整数値に変換するのに用いる。ほかにも、よく見ると
「CVTPD2DQ」のほかに「CVTTPD2DQ」という命令が載っている。違いは「CVT」と「CVTT」。
組み込み関数の方も「_mm_cvtpd_」「_mm_cvttpd_」といった具合でなんだか紛らわしい。見た目の違いは「cvt」「cvtt」。
「t」が付く付かないで変換される値が変わってしまうので注意が必要。
「_mm_cvt」の方は現在設定されている丸めモードに従って変換、「_mm_cvtt」のように「t」が2つ付く方は切り捨てて変換となる。
丸めモードは「直近値への丸め」、「切り上げ」、「切り捨て」、「ゼロ方向への丸め」があり、プログラマーが任意に指定できる。既定の丸めモード、つまり何も指定しなかった場合は、一番近い値に丸められる。
アプリを作って実行した際、演算結果が期待と大きく違ってしまうヒトはこの辺の事柄が飲み込めていないのかも。
丸めモードを指定するのはそれほど難しくない。Windows 用のアプリをC/C++ 言語 で作成するとして、FPU を介した演算ならば、_control87、_controlfp などのランタイム関数を呼び出すことで丸め動作を変更できる。
XMM レジスタを介した演算では _mm_setcsr 関数で同様の指定が可能である。
念のため書いておくが、_mm_setcsr 関数を用いて丸めモードを自由に変更できるとはいえ、演算ループが終了したら変更前に戻すのが無難である。

_mm_getcsr 関数を用いることで制御レジスタの内容を読み出せる。読み出した値をどこかに保持しておき、演算の繰り返しが終わり次第、制御レジスタの内容を元の値に戻すのが良いだろう・・・
実数で演算し結果を整数に変換する場合、実行速度を左右する項目があります。・・・ちなみに、この話の旨は XMM レジスタの活用であって、FPU の活用ではありません・・・
開発環境が Visual Studio 、32ビット版のアプリを作成する、演算は FPU を介するとしよう。整数に変換する際、何も指定しないと _ftol や _ftol2 といったヘルパー関数を呼び出して処理する。先に述べた通り、ソフトウェアによる代替処理は速くない。
もちろん、FPU が直接変換して値を返すことも可能である。重複するが、FPU が標準搭載されるようになったのは Pentium の登場からである。初期の Pentium において演算回路に欠陥を抱えたモノが出回った。ハードウェアレベルでの間違いを正すためにヘルパー関数を呼び出す。
逆にいえば、FPU による 直接変換ならば速度低下を避けられそうだ。標準仕様による _ftol や _ftol2 といったヘルパー関数を呼び出すのが遅い原因だとすれば、呼び出さないように指定すれば改善されるかも。
Visual Studio で/QIfistオプションを指定することで浮動小数点型から整数型への変換が必要なときのヘルパー関数 _ftol を呼び出さなくなる。つまり、FPU による 直接変換を行うようなアプリが生成される。たいていの場合、遅い部分が改善される。
Visual Studio で何らかのオプションを指定したい場合、プロジェクトの「プロパティページ」 ダイアログ ボックスを開く。ところが、/QIfistオプションを指定する項目は見つからない。
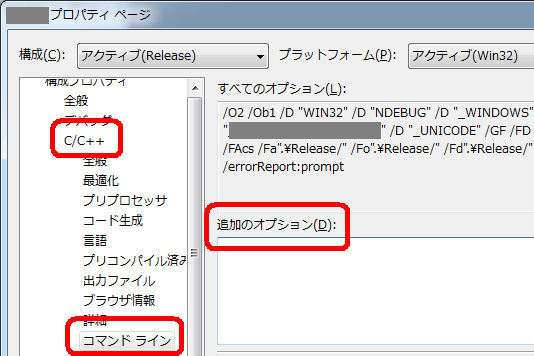
プロジェクトの [プロパティ ページ] ダイアログ ボックスを開き、左ペインの[C/C++] をクリック。続いて、[コマンド ライン] プロパティ ページをクリック。
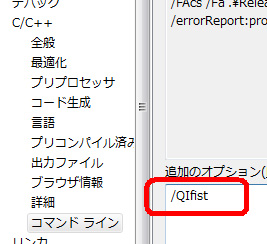
[追加のオプション] の入力欄に「/QIfist」と入力。
※ 初期の Pentium プロセッサーでなくとも演算結果が期待通りにならないリスクもあります。よって、このオプションを使うかどうかは慎重に・・・
あ、忘れるところでした。_ftol や _ftol2 でエラーになる件。
コンパイラとリンカーの相性が悪いとアプリ作成時にエラー。原因はコンパイラとリンカーのバージョンが合っていないこと。浮動小数点型から整数型への変換で _ftol2 関数 が使われるようになったのは西暦 2003 年頃リリースされた Visual Studio .net や同 2003 から。それ以前の Visual Studio 6.0 等では _ftol 関数 を用いたアプリとなる。
大雑把に言えば、Windows XP を念頭に置いた開発環境とそれ以前の Windows 98 や NT 4.0 を対象とした開発環境といったところ。実は、Microsoft Visual Studio 6.0 と Visual C++ Toolkit 2003 を組み合わせることが可能であった。この組み合わせにおいて、コンパイラが _ftol2 を指示してしまうが、リンカは古い方を探しに行ってしまい、結局エラーとなる。
ソースファイルの先頭の方に
・・・といったオマジナイを加えることで解消できたような・・・
開発環境を整えておくことでこのようなトラブルは防げる。Visual Studio の新バージョンが登場すると導入したくなる。新バージョンを導入する際、ついつい古いバージョンも残しておきたくなる。新旧共存させたい気持ちもわからなくはない。新しいモノに不具合はツキモノ。とはいえ、古いモノでは機能が足りない感が否めない。さらに、複数の PC に分けるのも手間がかかる。
一台の PC で済ませたいならば、VMWare 等の仮想環境を検討すると良い・・・
さてさて、XMM レジスタを活かした除算の高速化に話を戻しましょう。
冒頭に載せたようなアプリを組みたいとします。想いつく流れをおおまかに示すと
・整数値のデータを読み出す
・整数から倍精度浮動小数点値へ変換
・浮動小数で演算
・演算結果を整数に変換
・結果をメモリにストア ( 格納 )する・・・
・・・といった具合でしょうか。
長くなりましたので今回はこの辺で・・・

例えば、音遊びに使うアプリを作るとしよう。これは、音とび ( クリッピングが生じた音声データ ) を修正するために組んだアプリである。
もとの音データは整数値で収納されている。アプリはそれを読み出し、乗算・除算・三角関数などを通して処理して保存する。

アプリを使う側の視点で考えてみよう。演算が遅いということは待ち時間が増える。画像や音を編集するアプリを利用する際、多かれ少なかれ待ち時間が発生する。多く待たされることはストレスにつながる。数十秒で終わるのか、はたまた、一時間近く待たされるのか・・・
お知らせ
活動休止にともない、この記事を事前に予約投稿してあります。
トップ記事の固定を目的としています
※ これを下書きしたのは2012年夏の終わり頃です。
ご覧いただいている時期によっては状況が異なっている可能性があります。
下書きした頃の環境は、OS - Microsoft Windows 7、開発環境 - Visual Studio 2008 , C/C++ 言語。
Intel 80386 ( i386 ) の流れを汲む Core i7 や Pentium や Atom 等 の CPU もしくは互換品を前提としています。
予め述べておくが、
C/C++ 言語でいうところの変数の型や型変換など、基礎的な事柄の理解が曖昧なままここに辿りついたヒトもいることだろう。この先の内容を飲み込むのは辛いと思われる。ほかのプログラミング言語を用いるにしろ、そのようなヒトは除算の高速化うんぬんの前に基礎的な事柄を習得した後、再度ご覧頂ければ幸いである・・・
少しおさらい。
「除算が遅い」の補足 (6)で2組分の除算を行える~~~待ち時間はほぼ一緒。と述べた。
並列に実行できる、できないに関して手順を練り直すことで、さらなる高速化を目指せる。
なぜ XMM レジスタの明示的な利用するのかについては、「除算が遅い」の補足 (3)や「除算が遅い」の補足 (4)で綴ったように、
レジスタ数に余裕があるか否かで実行速度が左右されるからである。
※ 汎用レジスタは標準装備 ( もともと備わっていた )、XMM レジスタは後から追加された。
32ビット版の OS で実行するアプリを作成した際、空きレジスタの不足を補うようなコードが生成されることがあり、速度低下の要因になる。64ビット版の OS 上で32ビット版 のアプリを実行することは可能であるが、これは解消されない。
つぎに、64ビット版の OS 向けにアプリを作成した場合、32ビット版に比べ汎用レジスタ数に余裕がある。汎用レジスタで64ビット数値を直接扱える。したがって、XMM レジスタを積極的にメリットが薄いように感じてしまう。
64ビット版のアプリでは FPU を介した演算がサポートされない。西暦1993年頃に登場した Pentium から FPU ( 浮動小数点演算処理装置 ) が標準搭載されるようになった。そのほか、XMM レジスタでの演算は、FPU を介するのに比べ、同時に2組分の演算をこなせるので待ち時間を減らすことに繋がる。FPU の内部での演算精度が 80ビットである点は魅力的ではあるが・・・
しかし、前回綴ったように、SSE2 命令体系の中に整数の除算が含まれていない。
誤解が生じるといけないので、「命令が備わっていない。」と表現した方が適切だろうか。ハードウェア内部には除算を行う回路が備わっていても、それを呼び出す命令が存在しない。
もちろん、ソフトウェアレベルでの代替は可能である。しかし、「除算が遅い」の補足 (1)や「除算が遅い」の補足 (3)で触れたように、ソフトウェアレベルでの代替処理に速さ求めても仕方がない。
その後、SSE4.2 に至るまで整数の除算命令は追加されなかった。では、整数の除算に関して諦めるしかないのだろうか?
前回、XMM レジスタで倍精度浮動小数点値と 32 ビット整数値、もしくはその逆の変換が可能とヒントを載せた。
C/C++ 言語でいうところの型変換 ( キャスト) が判っていれば理解し易いハズ。
いま、どの型で演算しようとしているのか???等の基礎が曖昧なままアプリ作成を続けているヒトもいることだろう。昨今はプログラミングに親しみやすいようにとの計らいで、その辺を深入りせずともアプリを組めるようになってきた。とはいえ、上の段階に歩を進めようとした際に戸惑うことがないよう、基礎固めは重要・・・
この記事は Core i7 や Pentium や Atom 等 の Intel 80386 ( i386 ) の流れを汲む CPU を前提にしている。
一般的な PC の CPU は自動車でいうところのエンジンに該当する。西暦1993年頃に登場した Pentium から FPU が標準搭載され浮動小数点数 ( 実数 )を直接扱えるようになった。それまでは 別売りの FPU を追加するか、FPU を介しないソフトウェアによる代替で処理するようなアプリを組む必要があった。
もっと遡れば、CPU が直接扱えるのは 整数に限られていた時期もある。諸説あるが、電子計算が行われるようになったのは西暦1946年頃と言われている。現在用いられている単精度や倍精度浮動小数点数演算の標準化が行われたのは西暦1985年ごろ・・・
整数しか扱えない不便さは想像し難いだろうか。
例えば、本体価格10円、そこに5%の税金が乗るとしよう。人間の頭では一個10.5円と考えることができる。
いちばん小さい通貨の単位が1円であるならば、切り捨てて10円、切り上げて11円。前者では売る側が0.5円を負担、後者なら買う側が多く支払うことになる。どこか不公平。
もちろん、毎回2個一組での売買に定め、値段は21円に設定するなどの策も考えられるのだが・・・
XMM レジスタを用いて整数から倍精度浮動小数点値に変換する、または、その逆の命令 (倍精度浮動小数点値から整数に変換する ) を知りたい場合、
・IA-32 インテル アーキテクチャ ソフトウェア・デベロッパーズ・マニュアルや
・インテル エクステンデッド・メモリ64 テクノロジ・ソフトウェア・デベロッパーズ・ガイド等の書物が役立つ。もちろん無料。それら資料の入手に関しては過去記事車輪の再発明 (8)をご覧あれ。
「変換」は「convert」「conversion」「transformation」。IA-32 インテル アーキテクチャ ソフトウェア・デベロッパーズ・マニュアルは4巻。そのうち、中巻A:命令セット・リファレンスA-M。おそらく、「conv~~」「cvt~~」の項を眺めると何か見つかる。

CPU が直接解釈できるような機械語コードやCVT○○○といった擬似コードを覚えるのは苦労する。
C/C++ 言語でアプリを作成するなら組み込み関数を利用する。開発環境が Visual Studio だとすれば、「_mm_cvtepi32_pd」 と 「_mm_cvtpd_epi32」 の組み込み関数を用いることが可能。前者が整数から倍精度浮動小数への変換、後者はその逆。
「_mm_ ○△□」といった関数名を覚えるのが面倒!?!?!?
それに関しては「除算が遅い」の補足 (6)で触れたように「_mm_ ○△□ _pd」といった組み込み関数は「○△□」の部分が掛け算なら 「MUL」 、 割り算なら「DIV」と理解できる。同様に、数値を変換したい際に用いる組み込み関数の名は
「_mm_cvt」、「変換もと変数の型」、アンダースコア ( 下線 )、「変換される変数の型」の順に並んでいると理解できるハズ。
例えば、「_mm_cvtsd_si32」という組み込み関数であれば、倍精度浮動小数点値を符号付き 32 ビット整数値に変換するのに用いる。ほかにも、よく見ると

「CVTPD2DQ」のほかに「CVTTPD2DQ」という命令が載っている。違いは「CVT」と「CVTT」。
組み込み関数の方も「_mm_cvtpd_」「_mm_cvttpd_」といった具合でなんだか紛らわしい。見た目の違いは「cvt」「cvtt」。
「t」が付く付かないで変換される値が変わってしまうので注意が必要。
「_mm_cvt」の方は現在設定されている丸めモードに従って変換、「_mm_cvtt」のように「t」が2つ付く方は切り捨てて変換となる。
丸めモードは「直近値への丸め」、「切り上げ」、「切り捨て」、「ゼロ方向への丸め」があり、プログラマーが任意に指定できる。既定の丸めモード、つまり何も指定しなかった場合は、一番近い値に丸められる。
アプリを作って実行した際、演算結果が期待と大きく違ってしまうヒトはこの辺の事柄が飲み込めていないのかも。
丸めモードを指定するのはそれほど難しくない。Windows 用のアプリをC/C++ 言語 で作成するとして、FPU を介した演算ならば、_control87、_controlfp などのランタイム関数を呼び出すことで丸め動作を変更できる。
XMM レジスタを介した演算では _mm_setcsr 関数で同様の指定が可能である。
念のため書いておくが、_mm_setcsr 関数を用いて丸めモードを自由に変更できるとはいえ、演算ループが終了したら変更前に戻すのが無難である。

_mm_getcsr 関数を用いることで制御レジスタの内容を読み出せる。読み出した値をどこかに保持しておき、演算の繰り返しが終わり次第、制御レジスタの内容を元の値に戻すのが良いだろう・・・
実数で演算し結果を整数に変換する場合、実行速度を左右する項目があります。・・・ちなみに、この話の旨は XMM レジスタの活用であって、FPU の活用ではありません・・・
開発環境が Visual Studio 、32ビット版のアプリを作成する、演算は FPU を介するとしよう。整数に変換する際、何も指定しないと _ftol や _ftol2 といったヘルパー関数を呼び出して処理する。先に述べた通り、ソフトウェアによる代替処理は速くない。
もちろん、FPU が直接変換して値を返すことも可能である。重複するが、FPU が標準搭載されるようになったのは Pentium の登場からである。初期の Pentium において演算回路に欠陥を抱えたモノが出回った。ハードウェアレベルでの間違いを正すためにヘルパー関数を呼び出す。
逆にいえば、FPU による 直接変換ならば速度低下を避けられそうだ。標準仕様による _ftol や _ftol2 といったヘルパー関数を呼び出すのが遅い原因だとすれば、呼び出さないように指定すれば改善されるかも。
Visual Studio で/QIfistオプションを指定することで浮動小数点型から整数型への変換が必要なときのヘルパー関数 _ftol を呼び出さなくなる。つまり、FPU による 直接変換を行うようなアプリが生成される。たいていの場合、遅い部分が改善される。
Visual Studio で何らかのオプションを指定したい場合、プロジェクトの「プロパティページ」 ダイアログ ボックスを開く。ところが、/QIfistオプションを指定する項目は見つからない。

プロジェクトの [プロパティ ページ] ダイアログ ボックスを開き、左ペインの[C/C++] をクリック。続いて、[コマンド ライン] プロパティ ページをクリック。

[追加のオプション] の入力欄に「/QIfist」と入力。
※ 初期の Pentium プロセッサーでなくとも演算結果が期待通りにならないリスクもあります。よって、このオプションを使うかどうかは慎重に・・・
あ、忘れるところでした。_ftol や _ftol2 でエラーになる件。
コンパイラとリンカーの相性が悪いとアプリ作成時にエラー。原因はコンパイラとリンカーのバージョンが合っていないこと。浮動小数点型から整数型への変換で _ftol2 関数 が使われるようになったのは西暦 2003 年頃リリースされた Visual Studio .net や同 2003 から。それ以前の Visual Studio 6.0 等では _ftol 関数 を用いたアプリとなる。
大雑把に言えば、Windows XP を念頭に置いた開発環境とそれ以前の Windows 98 や NT 4.0 を対象とした開発環境といったところ。実は、Microsoft Visual Studio 6.0 と Visual C++ Toolkit 2003 を組み合わせることが可能であった。この組み合わせにおいて、コンパイラが _ftol2 を指示してしまうが、リンカは古い方を探しに行ってしまい、結局エラーとなる。
ソースファイルの先頭の方に
| extern "C" long _ftol2( double dblSource ) {return _ftol( dblSource );} |
開発環境を整えておくことでこのようなトラブルは防げる。Visual Studio の新バージョンが登場すると導入したくなる。新バージョンを導入する際、ついつい古いバージョンも残しておきたくなる。新旧共存させたい気持ちもわからなくはない。新しいモノに不具合はツキモノ。とはいえ、古いモノでは機能が足りない感が否めない。さらに、複数の PC に分けるのも手間がかかる。
一台の PC で済ませたいならば、VMWare 等の仮想環境を検討すると良い・・・
さてさて、XMM レジスタを活かした除算の高速化に話を戻しましょう。
冒頭に載せたようなアプリを組みたいとします。想いつく流れをおおまかに示すと
・整数値のデータを読み出す
・整数から倍精度浮動小数点値へ変換
・浮動小数で演算
・演算結果を整数に変換
・結果をメモリにストア ( 格納 )する・・・
・・・といった具合でしょうか。
長くなりましたので今回はこの辺で・・・
本日も最後までご覧いただきありがとうございます。
「つまらなかった」「判り辛った」という方もご遠慮なくコメント欄へどうぞ