答え:スクショからシェルのコマンドに渡す値を生成する
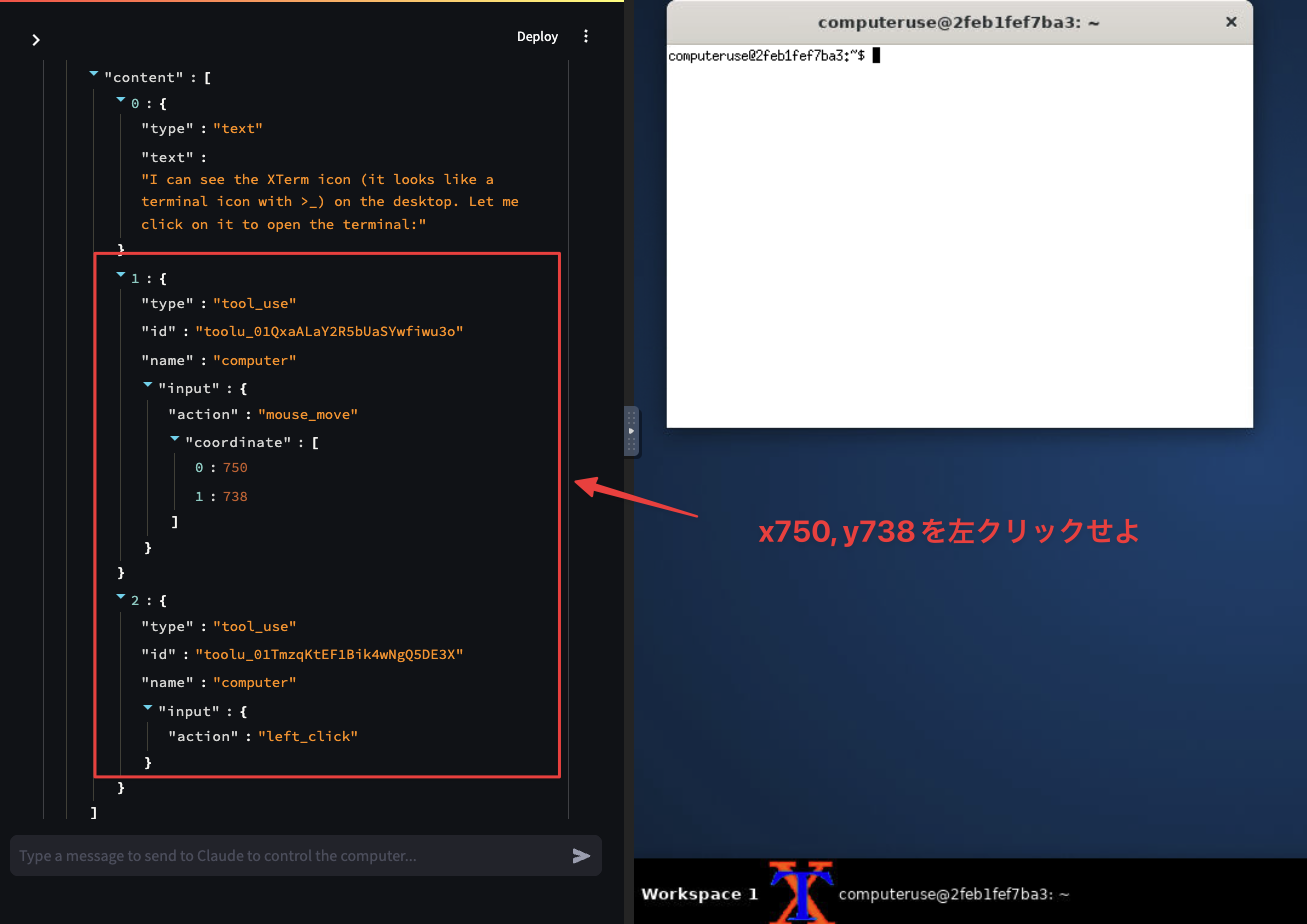
await asyncio.create_subprocess_shell("xdotool mousedown 1 mousemove --sync 750 738 mouseup 1")
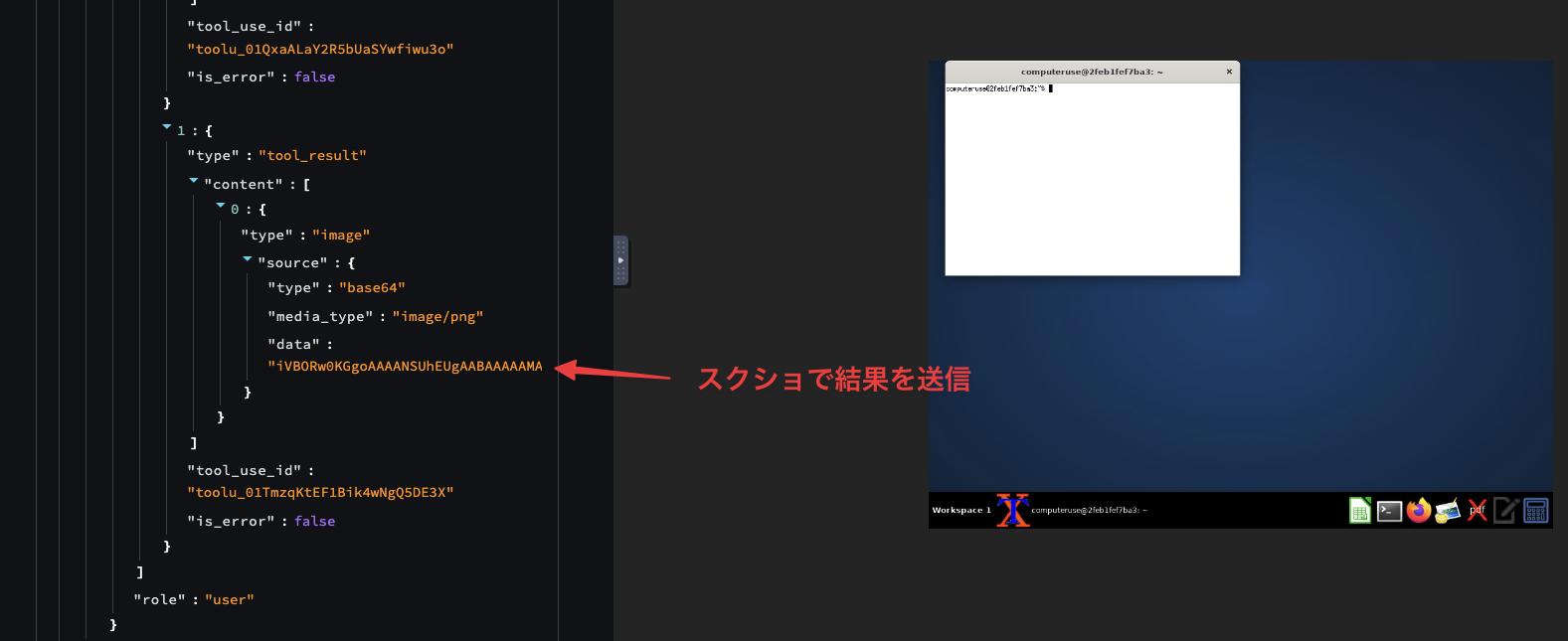
🤖「ヨシ!」
さらに詳しく
Anthropic Computer Useは、Claudeにコンピューター操作を指示するためのツールセットです。
この機能は既存のMessages APIを拡張する形で提供され、Computer tool、Text editor tool、Bash toolなどの関連ツールを含んでいます。
これらのツールにより、AIはデスクトップ環境の操作、ファイルの編集、シェルコマンドの実行など行うことが可能になります。
実装にあたっては、AnthropicがGitHub上で公開しているデモアプリの参照実装を利用できます。この実装はDocker上で動作し、StreamlitアプリケーションをユーザーインターフェースとしてClaudeとのインタラクションを可能にします。
APIの使用フローは、システムプロンプト、ツール定義、ユーザープロンプトの送信から始まります。Claudeはこれらの入力を基にツールの使用を判断し、実行指示を返します。開発者はこの指示に基づいてツールを実行するコードを実装し、その結果をAIに返します。このプロセスは、タスクが完了するまで繰り返されます。
処理の中核となるのは、ユーザーの指示に基づいてツールを実行し、結果を分析するループです。
Claudeはこのループを通じて、タスクの進捗を評価し、必要に応じて追加のアクションを実行します。例えば、ファイルの作成やテキストの書き込みといったタスクでは、複数のツールを組み合わせて使用し、各ステップの結果を確認しながら処理を進めます。
Anthropic Computer Use の概要
docs.anthropic.com
Anthropic Computer Use は、専用の API として提供されているわけではありません。
既存の Messages API に新しいツール1が追加される形で提供されます。
これらのツールは、computer-use-2024-10-22 という betaフラグを通じて有効にできます。
Messages API で使用可能なツール:
- Computer tool (
computer_20241022):
- デスクトップ環境を操作するためのツールです。
- マウスとキーボード操作をエミュレートし、スクリーンショットを取得できます。
- アプリケーションの実行、テキスト編集、ファイル操作などを実行可能です。
- 画面の解像度とディスプレイ番号を指定できます。
- Text editor tool (
text_editor_20241022):
- ファイルの表示、作成、編集を行うためのツールです。
- デスクトップ環境を必要とせずにファイル操作が可能です。
- テキスト生成やコーディングなどのタスクに利用できます。
- Bash tool (
bash_20241022):
- シェルコマンドを実行するためのツールです。
- デスクトップ環境を必要とせずにコマンド操作が可能です。
- ファイル一覧の取得、パッケージのインストール、コマンドの実行などが可能です。
これらのツールは Anthropic によって定義されていますが、ユーザーがツールの実行結果を評価する処理を実装して、結果をtool_results として返す必要があります。
処理の実行指示はAPIから送られてきますが、実行処理は開発者が実装します。
Messages APIとの統合:
- 開発者は、API リクエストにツール定義を含めることで、Claude にコンピューター操作を指示できます。
- Claude は、ツールの実行が必要と判断した場合、
tool_use を含むレスポンスを返します。
- 開発者は、
tool_use レスポンスからツール名と入力を抽出し、対応するツールを実行します。
- ツールの実行結果は、
tool_result を含む新しいユーザーメッセージとして Claude に送信されます。
実装例と使用方法
Anthropic は、Computer Use API を使用したデモアプリの参照実装を GitHub で公開しています。
github.com
この参照実装は、Docker コンテナ内で動作し、Anthropic API(もしくはBedrock、Vertex) を通じて Claude 3.5 Sonnet モデルにアクセスします。
ユーザーインターフェイスとしてStreamlit アプリが含まれています。 これはチャット機能とコンテナ内のデスクトップをリアルタイムに表示する機能を提供します。
デモアプリが操作する対象のシステムはDocker コンテナ内で動作します。
コンテナ内のUbuntuデスクトップに必要な依存関係 (Ubuntu 22.04、xvfb、xterm、xdotool、scrot、imagemagick、sudo、mutter、x11vnc、Python 3.11.6 など) をセットアップします。
ここからPythonでMessages API を通じて Anthropic の Claude モデルと通信し、ツールを利用します。
起動方法については、Anthropic API を使用する場合は、ANTHROPIC_API_KEY 環境変数を設定して Docker コンテナを起動します。 Bedrock または Vertex を使用する場合は、それぞれの認証情報を設定する必要があります。
デモアプリの起動コマンド:
export ANTHROPIC_API_KEY=%your_api_key%
docker run \
-e ANTHROPIC_API_KEY=$ANTHROPIC_API_KEY \
-v $HOME/.anthropic:/home/computeruse/.anthropic \
-p 5900:5900 \
-p 8501:8501 \
-p 6080:6080 \
-p 8080:8080 \
-it ghcr.io/anthropics/anthropic-quickstarts:computer-use-demo-latest
http://localhost:8501 で Streamlitアプリ単体を。http://127.0.0.1:6080/vnc.html でVNCビュワーを。
http://localhost:8080 で Streamlit + VNCビュワーをiframeで統合した画面にアクセスできます。
VNC サーバーと NoVNC を使用した接続
デモアプリでは、コンテナ内でVNC サーバー (x11vnc) を起動し、ビュワーから NoVNC を使用して接続します。
NoVNC は、Web ブラウザ上で VNC 接続を可能にするクライアントです。
ユーザーはブラウザ上のVNCビュワーから Docker コンテナ内のデスクトップ環境にアクセスできます。
右上の「Toggle Screen Control (On)」ボタンを押すとデスクトップを操作できるようになります。
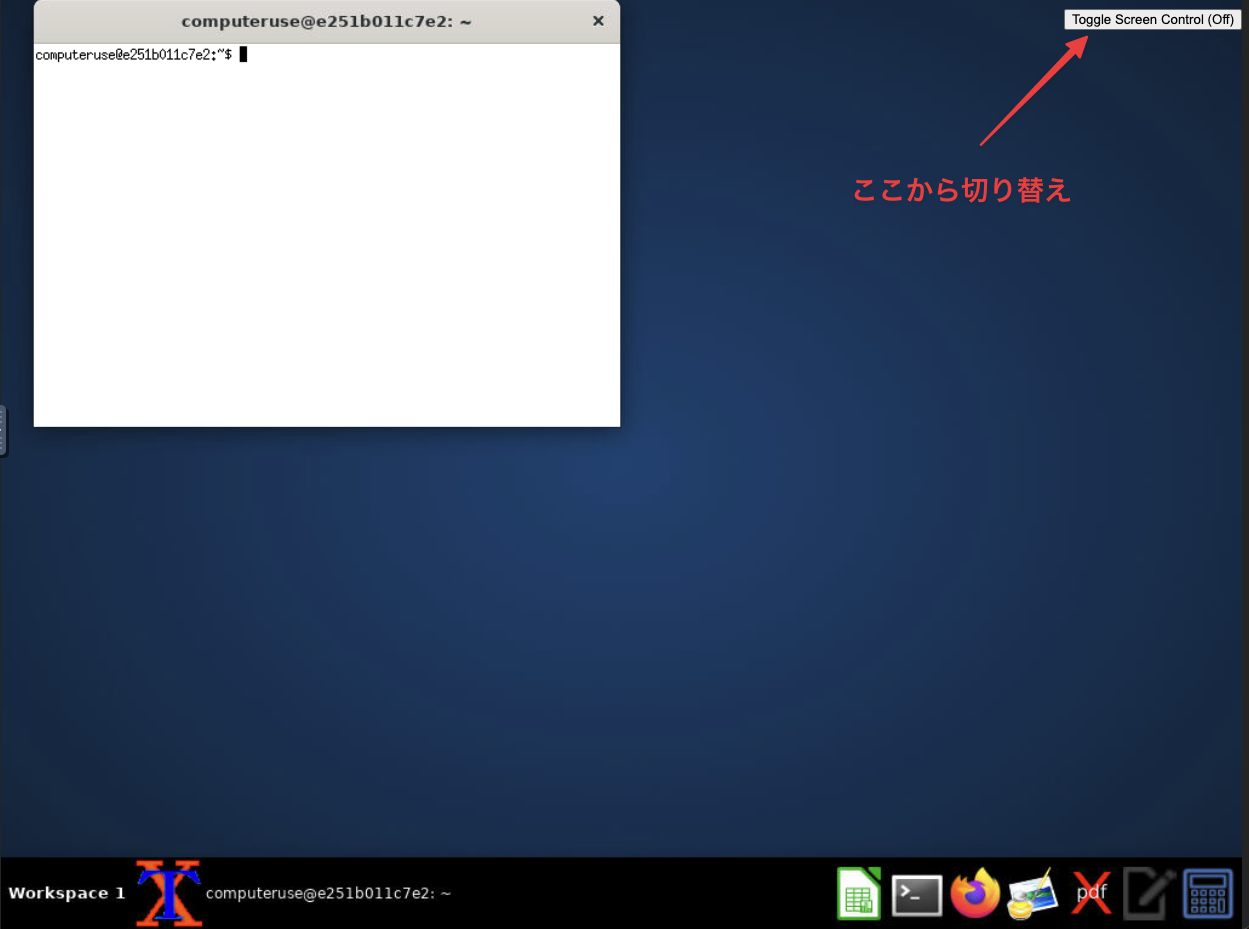
ツールでの自動実行がうまくいかない場合、デスクトップを手動で操作してデバッグすることができます。
先のとうり、 http://localhost:6080/vnc.html にアクセスすることで、単独のウィンドウで開くことができます。
また、任意の VNC クライアントからも直接 vnc://localhost:5900 で接続可能です。
このVNCビュワーについてはComputer Useに必須というわけではなく、主にデモ用+デバッグ用になります。
ユーザー向けのUIは主にStreamlitアプリ(http://localhost:8501)の方になるでしょう。
送受信フロー
送信
システムプロンプト:
Claude がツールを使用するための指示と、ツールの動作に必要なコンテキストを提供します。
ツール定義、ツール設定、ユーザー指定のシステムプロンプトから構築されます。
でもアプリでは、これはSYSTEM_PROMPTで定義されています。
このプロンプトはUbuntuの仮想環境でbashツールを使用してアプリケーションを操作し、GUIアプリケーションを起動するためのガイドラインを提供しています。
tools:
Computer toolなどの利用するツールの設定情報などをパラメータとして送信します。
ユーザープロンプト:
チャットで入力した指示と現在のスクリーンショットを送信します。
受信
Tool 実行指示の受信と実行
Claude は、ユーザーのプロンプトに基づいて、どのツールを使用するか、どのパラメータを指定するかを判断します。
tool_use という stop_reason と共に、ツール名、入力パラメータなどを含むレスポンスが返ってきます。
ユーザー (クライアントコード) は、tool_use レスポンスから以下の情報を抽出します。
name: 使用するツールの名前
id: このツール使用ブロックの一意の識別子
input: ツールに渡される入力
ユーザーは、対応するツールを実行します。
computer_20241022 ツールの例:
action: 実行するアクションの種類 (例: key - キーボードのキーを押す, type - テキストを入力する, mouse_move - マウスを移動する, left_click - 左クリックする, screenshot - スクリーンショットを撮る)
coordinate: マウス移動などのアクションの座標を指定するタプル (オプション)text: 入力するテキスト (オプション)
コード例:
async def __call__(self, action: str, text: Optional[str] = None, coordinate: Optional[Tuple[int, int]] = None, **kwargs) -> ToolResult:
if action == "key":
elif action == "type":
elif action == "mouse_move":
elif action == "left_click":
text_editor_20241022 ツールの例:
command: 実行するコマンド (例: view - ファイルを表示する, create - ファイルを作成する, str_replace - 文字列を置換する)path: ファイルまたはディレクトリの絶対パスfile_text: 作成するファイルの内容 (オプション)old_str: 置換する文字列 (オプション)new_str: 新しい文字列 (オプション)
bash_20241022 ツールの例:
command: 実行する bash コマンドrestart: ツールを再起動するかどうか (オプション)
結果の保存
ツールの実行結果は、tool_resultを含む新しいユーザーメッセージとして Claude に送信されます。
tool_resultには、以下の情報が含まれます。
- tool_use_id: 結果が対応するツール使用リクエストの id
- content: ツールの結果 (文字列, 画像, その他のコンテンツブロック)
- is_error (オプション): ツールの実行がエラーになった場合は true に設定
スクリーンショットの base64:
computer_20241022 ツールの screenshot アクションでは、スクリーンショットが取得され、base64 エンコードされて tool_result の content に格納されます。
この base64 エンコードされた画像データは、sampling_loop メソッドを通じて Message API に送信されます。
コード例:
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "toolu_01A09q90qw90lq917835lq9",
"content": "15 degrees"
}
]
}
処理とループ
デモアプリは、ユーザーの指示に基づいてツールを実行し、その結果を分析して、タスクが完了するまで処理をループします。 このループはユーザー入力なしでMessage APIへの送受信を繰り返します。
ループ内でのスクリーンショット取得
ComputerTool クラスの screenshot メソッドは、gnome-screenshot scrot コマンドを使用してスクリーンショットを取得し、base64 エンコードして ToolResult オブジェクトに格納します。
この base64 エンコードされた画像データは、sampling_loop メソッドを通じて Message API に送信されます。
タスクを完了したと判断する基準
Claude は、ツールの実行結果とユーザーの指示に基づいて、タスクが完了したかどうかを判断します。
例えば、ユーザーが「猫の画像をデスクトップに保存する」ように指示した場合、Claude は画像がデスクトップに保存されたことを確認してタスクを完了と判断します。
その後の処理
タスクが完了したら、Claude はユーザーに最終的な応答を返します。
応答には、タスクの実行結果や、追加の質問などが含まれる場合があります。
具体的な処理の流れの例
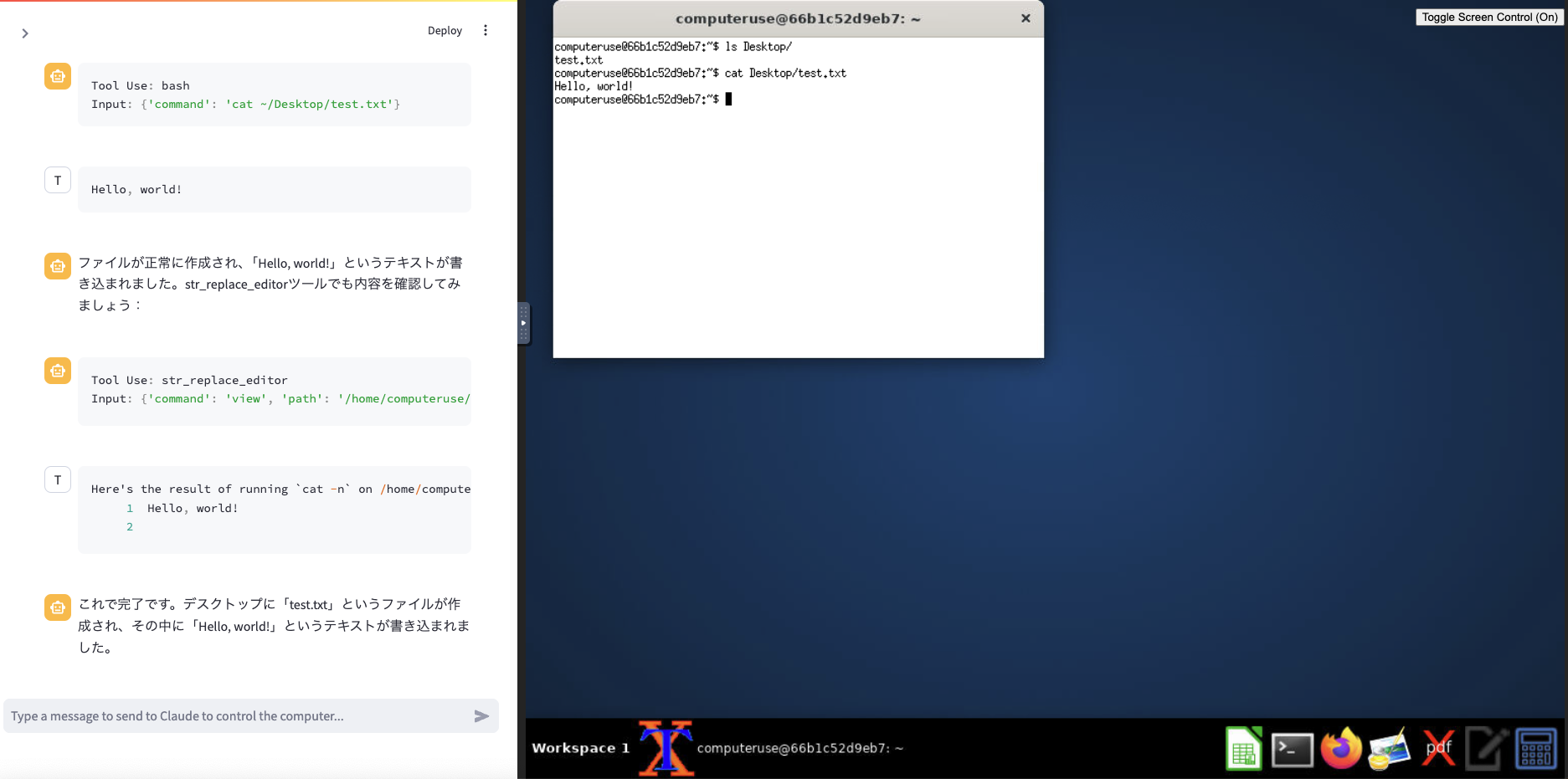
- ユーザーが「デスクトップに「test.txt」というファイルを作成し、「Hello, world!」というテキストを書き込んで保存してください。 」と指示します。
- Claude は、このタスクを完了するために、
bash_20241022 ツールと text_editor_20241022 ツールを使用する必要があると判断します。
- Claude は、
bash_20241022 ツールを使用して、一度実行をしますがDesktopディレクトリが存在しないことがわかります。
- Claude は、
bash_20241022 ツールを使用して、Desktop ディレクトリを作成します。
- Claude は、
bash_20241022 ツールを使用して、「test.txt」という名前の新しいファイルを作成し、「Hello, world!」というテキストを書き込みます。
- Claude は、
text_editor_20241022 ツールを使用して、ファイルの内容を確認します。
- Claude は、
bash_20241022 ツールを使用して、ファイルの内容を確認します。
- Claude は、API 経由で、スクリーンショットと「タスクが完了しました。 」というメッセージをユーザーに返します。
Code Interpreter系との違い
OpenAIのCode Interpreterは自然言語のタスクについて解決するソースコードを生成して、それをプラットフォームの実行環境で実行します。
一方、Computer Useは開発者が自分で用意した実行環境のシステムを操作するためのアクション+パラメータのみを生成します。実行するコードは開発者自身が用意します。
「デスクトップを特定の順で操作する」などタスクの解決策が明確な場合においては、実行コードは開発者で用意して、可変になるパラメータのみ生成する方が柔軟で安定して運用という特性があります。
Code Interpreteについては「データを何らかの方法で分析する」などのHOWが明確でない場合に、コードで表現可能な範囲を動的に検証できて引き続き有用なので、使い分けすることができます。
現在の制限
悪用防止のためのガードが入っているためか、SNSへの自動投稿やECサイトでの商品購入は行ってくれませんでした。
またスクロールや小さい領域のクリックが必要な操作は期待どうり動かないことが多いです。
料金に関してはMessage APIに画像をbase64化したデータを添えるのでかさみがちです。
デモアプリを小一時間テストすると1〜数ドルレベルの課金が発生すると思います。
おわりに
LLMアプリ開発コミュニティでも、このような自律的AIでのPC操作を実現する試みは以前から行われていました。 AutoGPTに代表されるようなプロジェクトがその一例です。
プラットフォーム各社のAPIが画像を送信できるようになったことで、これらの試みは以前よりも実現可能性が高まっています。
そして今回のComputer Useのようなプラットフォーマー自身によってPC操作自動化のAPIが提供されたことは大きな変化です。
開発元によって最初からPC操作自動化を想定したモデルのチューニングが行われているということだからです。
このような事例は、アプリ開発の分野では「シャーロックされる(Sherlocking)2」として知られています。 のび太がひみつ道具で遊んでると横からジャイアンが入ってくるやつです。
デモ映えするのはComputer toolを使った派手なRPAエージェントかもしれませんが、個人的には実用性を考えるとText editor toolやBash toolの方が早く現実のニーズに応えられる可能性が高いと感じます。
たとえば、これらのツールを使えば、Node.js以外にも対応するDocker版の「volt.new 3」のようなシステムを作ることができるでしょう。
またComputer UseはLinuxやDockerに閉じた仕組みではないのでWindowsやmacOSの環境でも実現できます(今のところbashを中心に自動化しているのでWSLではない純粋なWindowsのサーバー環境では厳しいとは思いますが)。
その場合、システムプロンプトを「私の環境は(macOS/Windows)です。」と変更することになります。
Anthropicがいうようにサンドボックス環境でないと意図しないオペレーションが実行されるリスクが大きいため使うことはできなさそうなので、外部環境から切り離された実行専用のミニPCやクラウドのインスタンスを用意するというのも考えられます。
")
/eMMC onboard 64GB/Windows 11pro 64ビット)【日本正規代理店品】 PN41-S1-BC306AD ブラック")




 (ビームコミックス)")